

Developing AWS Lambda Functions in SPL
1. Introduction
AWS Lambda provides convenient to use functions service, which allows running code without presetting or administering the server and which enables calling functions directly from any Web or mobile application to get expected result. We can read business data, perform complex computations and output the result to the caller in the function’s code. Data processing and computation, however, is complicated, involving heavy workload and time-consuming programming and debugging tasks. SPL is an excellent tool for performing data computations. It allows connecting to various types of data sources, including different databases and different formats of data files, offers an extremely rich collection of data computing functions that can implement the target computation with very concise code, and supplies easy to use visualized, stepwise debugging functionality. Writing Lambda functions in SPL to process and compute data can greatly reduce the workload of coding functions and increase development efficiency.
2. Write the runSPL function
2.1 Functionality of runSPL
runSPL function works to launch the SPL runtime environment, run the existing SPL script, and return the result to the function’s caller end in JSON format.
2.2 Parameters of runSPL
runSPL function receives two parameters – splx and parameters. splx specifies the location of an existing script file; parameters, whose format is a JSON string, represents parameters the splx script file uses.
2.3 Source code of runSPL
[RunSpl.java]
package com.scudata.lib.shell;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.net.URI;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.json.JSONObject;
import software.amazon.awssdk.auth.credentials.AwsBasicCredentials;
import software.amazon.awssdk.auth.credentials.StaticCredentialsProvider;
import software.amazon.awssdk.http.SdkHttpClient;
import software.amazon.awssdk.http.apache.ApacheHttpClient;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.S3ClientBuilder;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import com.scudata.app.config.ConfigUtil;
import com.scudata.app.config.RaqsoftConfig;
import com.scudata.app.config.RemoteStoreConfig;
import com.scudata.cellset.datamodel.PgmCellSet;
import com.scudata.common.Logger;
import com.scudata.dm.Env;
import com.scudata.dm.FileObject;
import com.scudata.dm.JobSpaceManager;
import com.scudata.ecloud.ide.GMCloud;
import com.scudata.ecloud.util.InitialUtil;
import com.scudata.ide.spl.Esprocx;
import com.scudata.lib.ctx.ImS3File;
import com.scudata.lib.lambda.ImUtils;
public class RunSpl implements RequestHandler<Map<String, Object>, Object> {
private static S3Client s3Client;
private com.scudata.dm.Context splCtx;
static {
InputStream stream = null;
try {
Logger.info("spl start........");
//Read the SPL configuration file in the deployment package
String xml = "/opt/java/config/raqsoftConfig.xml";
File f = new File(xml);
if (f.exists()) {
stream = new FileInputStream(f);
RaqsoftConfig rc = ConfigUtil.load(stream, true);
InitialUtil.loadAcloudFunctions(); //Load functions such as Qfile
GMCloud.initQJDBC( rc ); //Load the remote storage settings from the configuration file
List<RemoteStoreConfig> list = rc.getRemoteStoreList();
if( list != null && list.size() > 0 ) {
RemoteStoreConfig rsc = list.get( 0 );
JSONObject jo = new JSONObject( rsc.getOption() );
initS3(jo.getString("accessKey"), jo.getString("secretKey"), jo.getString("region"), jo.getString("endPoint"));
}
}
} catch (Throwable e) {
Logger.error("init SPL config error: " + e);
} finally {
try {
stream.close();
} catch (Throwable th) {}
}
}
public Object handleRequest(Map<String, Object> event, Context context) {
String ret = "";
try {
return doHandle(event, context);
}
catch( Throwable e) {
ret = e.getMessage();
Logger.error(e.getMessage());
}
return ret;
}
//Initiate the configurations for accessing S3
private static void initS3(String accessKey, String secretKey, String region, String endPoint) throws Exception {
SdkHttpClient httpClient = ApacheHttpClient.builder().build();
if (accessKey == null && secretKey == null) {
ImUtils.getS3Instance(region);
return;
}
AwsBasicCredentials awsCreds = AwsBasicCredentials.create(accessKey, secretKey);
StaticCredentialsProvider credentialsProvider = StaticCredentialsProvider.create(awsCreds);
S3ClientBuilder builder = S3Client.builder().httpClient(httpClient);
if (region != null && !region.trim().isEmpty()) {
Region reg = Region.of(region);
builder.region(reg);
}
if (endPoint != null && !endPoint.trim().isEmpty()) {
builder.endpointOverride(URI.create(endPoint));
}
s3Client = builder.credentialsProvider(credentialsProvider).build();
ImUtils.setS3Client(s3Client);
}
//Function’s handling method: event receives two parameters: splx and parameters, executes the specified script and returns the computing result
private Object doHandle(Map<String, Object> event, Context context) throws Exception {
String bucket = null;
String objName = null;
splCtx = Esprocx.prepareEnv(); //Prepare the script context
Object o = event.get("parameters");
parseParameterToCtx( o );
boolean isS3File = false;
String splx = "";
o = event.get("splx");
if (o != null && o instanceof String) {
splx = o.toString();
//A splx script heading with s3:// represents a file stored on S3
if( splx.toLowerCase().startsWith( "s3://" ) ) {
String[] vs = ImUtils.splitS3String( splx );
if (vs.length == 2) {
bucket = vs[0];
objName = vs[1];
}
isS3File = true;
}
}
else throw new Exception( "Function paramter value of splx is invalid." );
File splxFile = null;
if ( isS3File ) {
//Load the script from S3 to /tmp/bucket/objName
ImS3File s3File = new ImS3File(bucket + "/" + objName, "utf-8");
splxFile = s3File.getLocalFile();
System.out.println( "splxFile=" + splxFile);
if (splxFile == null || !splxFile.exists()) {
throw new Exception( bucket + "/" + objName + " is not existed" );
}
}
else {
splxFile = new File( splx );
}
FileObject fo = new FileObject( splxFile.getAbsolutePath(), "p" );
PgmCellSet pcs = fo.readPgmCellSet();
try {
//Execute the script
pcs.setContext( splCtx );
pcs.calculateResult();
}
finally {
JobSpaceManager.closeSpace( splCtx.getJobSpace().getID() );
}
Object ret = pcs.nextResult();
Logger.info("spl end ....");
Object jsonVal = ImUtils.dataToJsonString(ret);
return jsonVal; //Return the computing result in JSON format
}
//Set the parameters in the parameter string in the context splCtx
private void parseParameterToCtx( Object param ) {
if (param == null) return;
if (param instanceof String) { // for jsonString
String jsonVal = param.toString();
JSONObject json = new JSONObject(jsonVal);
Iterator<String> keys = json.keys();
while( keys.hasNext() ) {
String key = keys.next();
splCtx.setParamValue( key, json.get( key ) );
}
}
}
}
3. Deploying runSPL
Log in to the AWS account and enter the Lambda service page.
3.1 Create layers
Lambda layers contain resources, such as jar packages and configuration files, that functions can reference. Four layers will be created for runSPL:
1. myLayerLambdaS3: Deploy the jar files used for accessing S3 and Lambda API and compress these files into a deployment package named lambda_s3.zip, where jar files are located in the java/lib directory. The jar files come from esProc external library packages S3Cli and LambdaCli. The external library packages can be downloaded from the SPL official website.
2. myLayerSpl: Deploy jar files used for running SPL and compress these files into a deployment package named spl.zip, where jar files are located in the java/lib directory. The jar files come from the lib directory under the installed Enterprise SPL’s installation directory. In addition to the four jar files below, the others are the third-party jar packages SPL will reference:
esproc-bin-xxx.jar
esproc-ext-xxx.jar
esproc-ent-xxx.jar
ecloud-xxx.jar
xxx represents the date, and get the latest possible jar packages.
3. mySqlJdbc: Deploy the JDBC application package for connecting to Amazon RDS MySQL database. The package only contains one jar file: mysql-connector-j-8.3.0.jar, which can be downloaded from https://dev.mysql.com/downloads/connector/j/. Put the jar file in java/lib directory in* rds-mysql.zip*. To access any other database, just use their JDBC package.
4. runsplConfig: Deploy SPL configuration file *raqsoftConfig.xml *and related files. Our example involves the local script file *orders.splx *and the local composite table file orders.ctx. Compress them into deployment package config.zip, put raqsoftConfig.xml in java/config directory, and place orders.splx and orders.ctx in the root directory.
Below is content of raqsoftConfig.xml:
<?xml version="1.0" encoding="UTF-8"?>
<Config Version="3">
<Runtime>
<DBList encryptLevel="0">
<DB name="rds_mysql">
<property name="url" value="jdbc:mysql://mysql-free2.c3oygm4kw7lr.rds.cn-north-1.amazonaws.com.cn:3306/tpch?useCursorFetch=true"></property>
<property name="driver" value="com.mysql.jdbc.Driver"></property>
<property name="type" value="10"></property>
<property name="user" value="admin"></property>
<property name="password" value="esp…..p"></property>
<property name="batchSize" value="0"></property>
<property name="autoConnect" value="false"></property>
<property name="useSchema" value="false"></property>
<property name="addTilde" value="false"></property>
<property name="caseSentence" value="false"></property>
</DB>
</DBList>
<Esproc>
<charSet>GBK</charSet>
<splPathList>
<splPath>/tmp</splPath>
</splPathList>
<dateFormat>yyyy-MM-dd</dateFormat>
<timeFormat>HH????ss</timeFormat>
<dateTimeFormat>yyyy-MM-dd HH????ss</dateTimeFormat>
<mainPath>/tmp</mainPath>
<tempPath></tempPath>
<bufSize>65536</bufSize>
<parallelNum>32</parallelNum>
<cursorParallelNum>8</cursorParallelNum>
<blockSize>1048576</blockSize>
<nullStrings>nan,null,n/a</nullStrings>
<fetchCount>9999</fetchCount>
<extLibsPath></extLibsPath>
<customFunctionFile></customFunctionFile>
<RemoteStores>
<RemoteStore name="S3" type="S3" cachePath="/tmp" minFreeSpace="0" blockBufferSize="0">
{"dataKey":"","endPoint":"https://s3.cn-north-1.amazonaws.com.cn", "secretKey":"aYI3JBZOuRGk…….vNhjDhoVQU0yN","accessKey":"AKIA……IIIXO","region":"cn-north-1","type":"s3","bCacheEnable":true}
</RemoteStore>
</RemoteStores>
</Esproc>
<Logger>
<Level>DEBUG</Level>
</Logger>
</Runtime>
</Config>
In the file above, node <DB> contains configuration information for accessing Amazon RDS MySQL cloud database. Its contents need to be written according to information of the to-be-accessed cloud database or another type of database based on another cloud platform. There is no need to configure this node if you do not need to access the database. Both splPath and mainPath must be configured in the form of /tmp because only /tmp directory in Lambda virtual machine is writable. The S3 remote script and the remote data files will be stored in /tmp after they are downloaded. cursorParallelNum configures the number of parallel threads in the parallel processing function used in a SPL script; RemoteStore specifies the configuration information for accessing your S3 (no need to configure this property if S3 isn’t needed); cachePath should be also configured as /tmp.
Layers are created in the similar way. Let’s take the layer myLayerLambdaS3 as an example to look at the process:
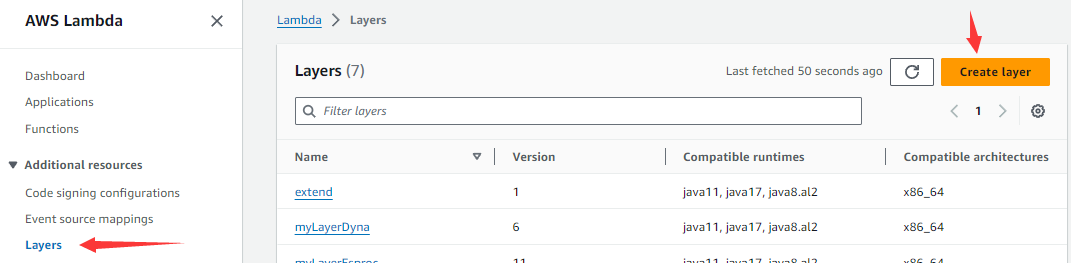
As the following screenshot shows, click “Layers” in the navigation menu on the left and then “Create layer” button on the right:
Then get into the page below:
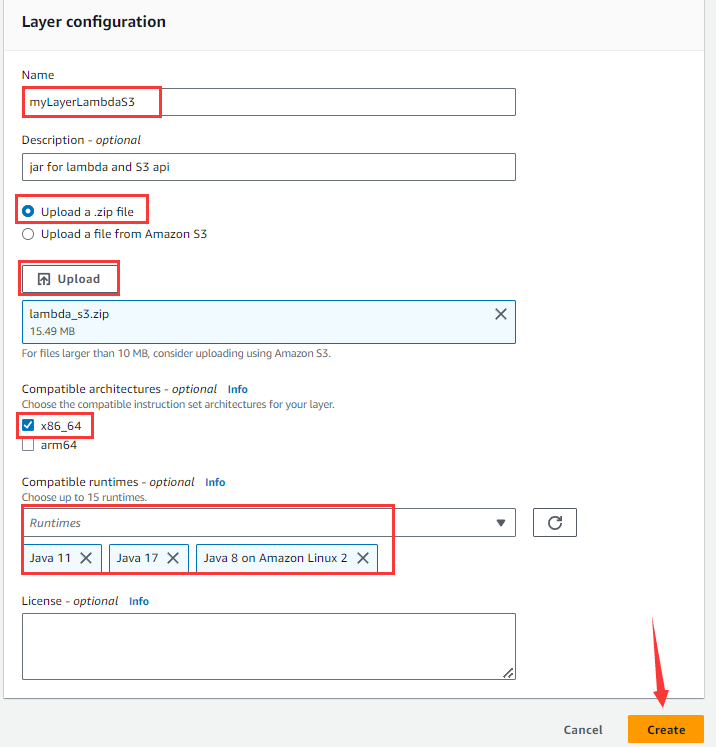
Enter Name, Description (optional), select “Upload a .zip file”, click “Upload” button, choose the compressed lambda_s3.zip, select x86_64 architecture, choose Java11, Java17 and Java8 for “Compatible runtimes”, and then click “Create” button.
If size of the zip archive is larger than 50M, they cannot be directly uploaded. Instead, they should be first uploaded to S3, then choose “Upload a file from Amazon S3” on this page and enter the zip file URL on S3.
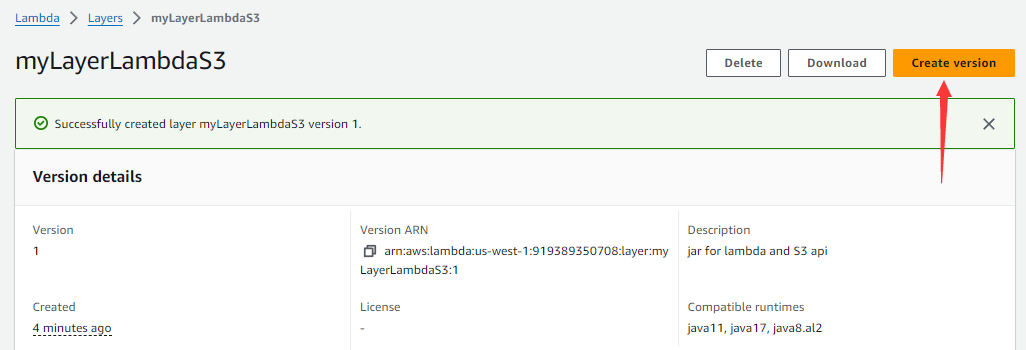
If the layer’s zip deployment package is changed, click the layer under “Layers” and then “Create version” button to re-upload the zip deployment package.
Below is the list of all created layers:
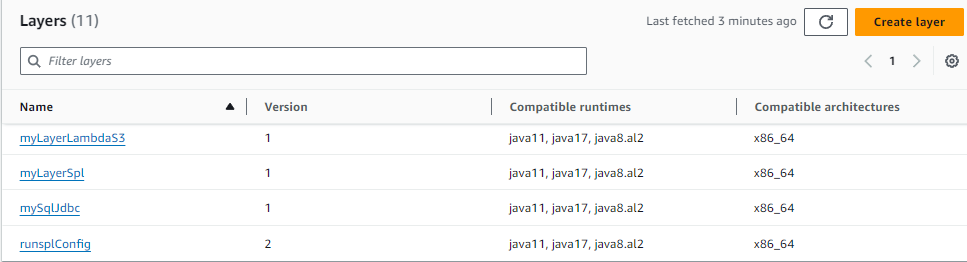 In which runsplConfig layer had a new version created during the testing.
In which runsplConfig layer had a new version created during the testing.
3.2 Create functions
Compile Java classes related to the runSPL function and package all class files into runSpl.jar file.
On the Lambda service page, select “Functions” in navigate menu on the left and click “Create function” button on the right.

Then get into the “Create function” page shown below:
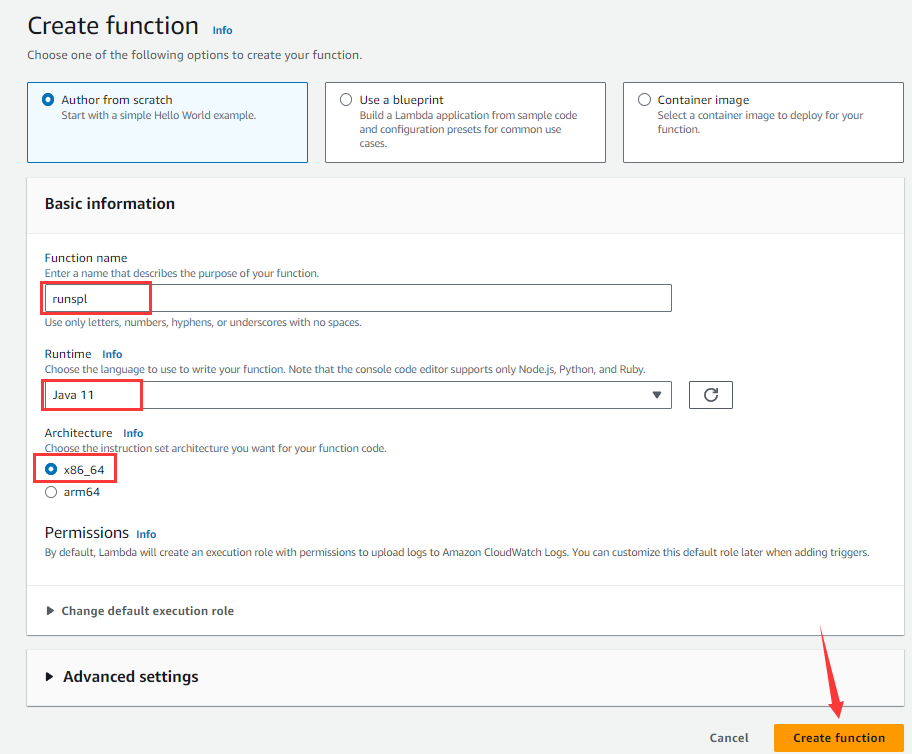
Enter runspl under “Function name”, select Java11 under “Runtime”, choose x86_64 under “Architecture”, and click “Create function” button to enter the page shown below:
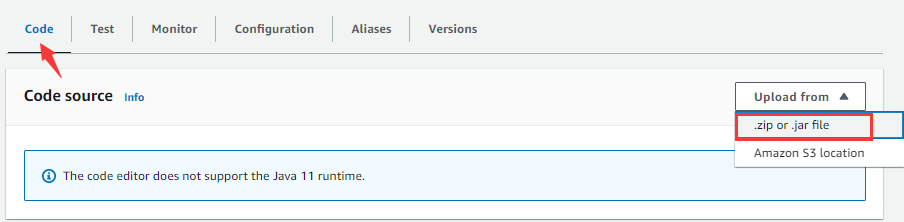
On “Code” tabpage, click “Upload from” drop-down list and click “.zip or .jar file” to pop up the following window:
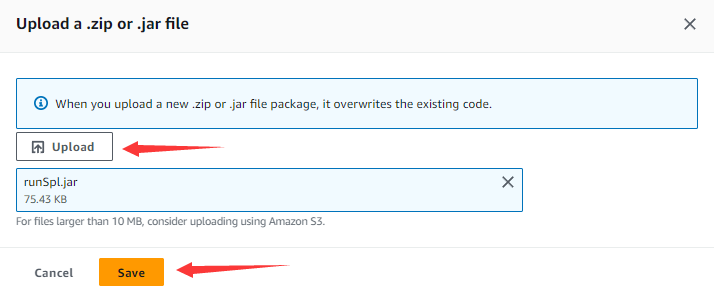
Click “Upload” button, choose the prepared runSpl.jar file and click “Save” button.
On the “Code” tabpage, click “Edit” button under “Runtime settings”:
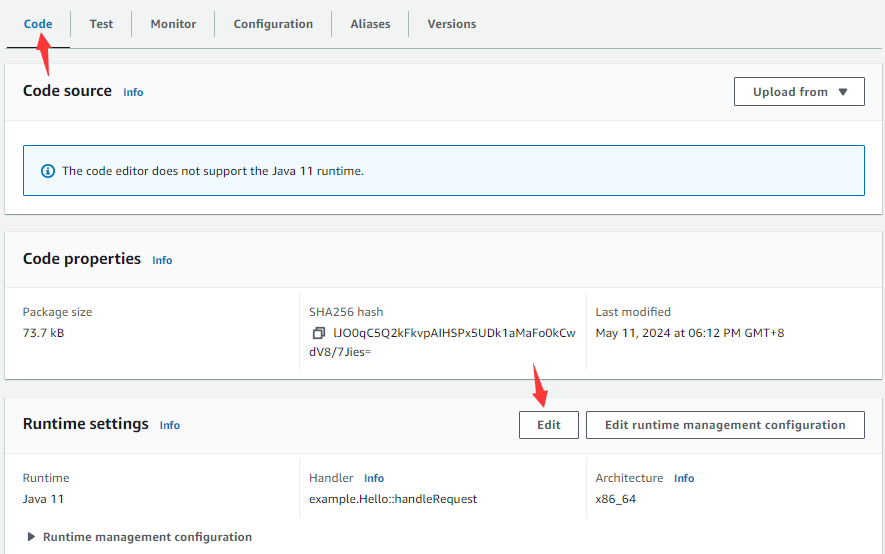
And get into the following page:
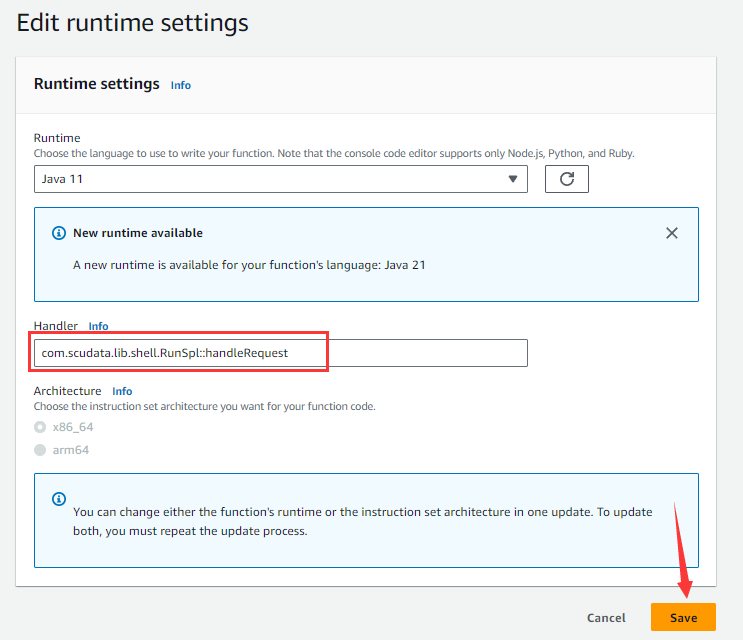
Type in function class name and handle method in the “Handler” input box, click “Save” button to return to the “Code” tab, and click “Add a layer” button:
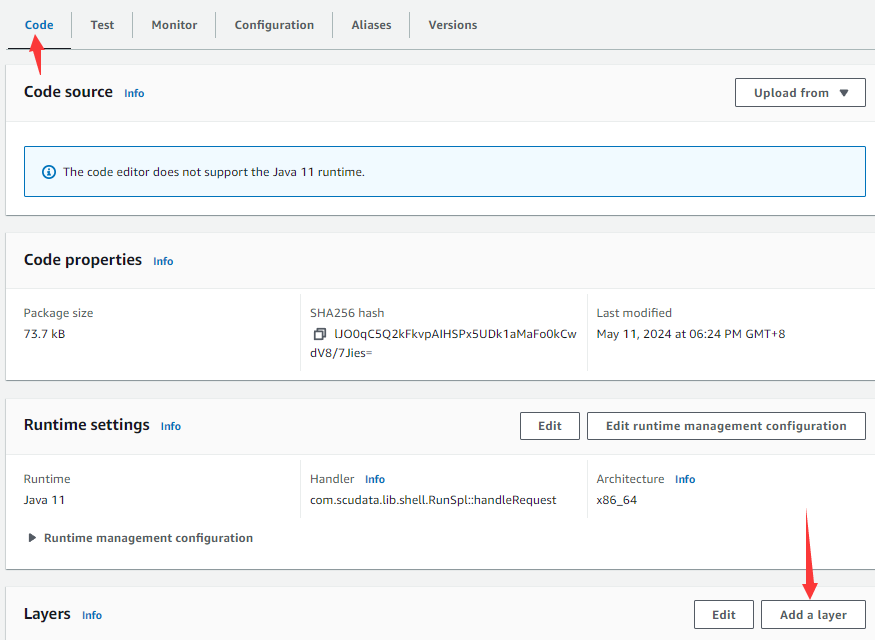
And enter “Add layer” page shown below:
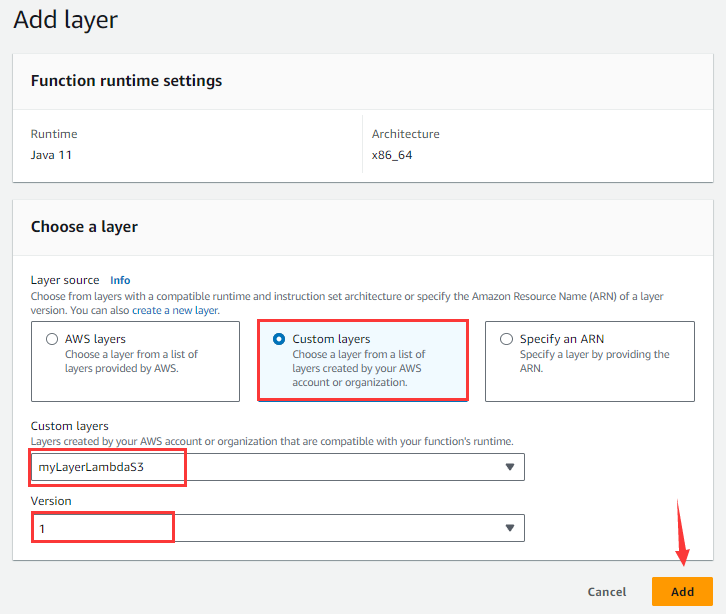
Select “Custom layers”, choose myLayerLambdaS3 among Custom layers’s drop-down list and 1 for “Version”, and click “Add” button.
Repeat the operations for adding a layer to add myLayerSpl, mySqlJdbc, runsplConfig and more layers.
Then enter “Configuration” tabpage:
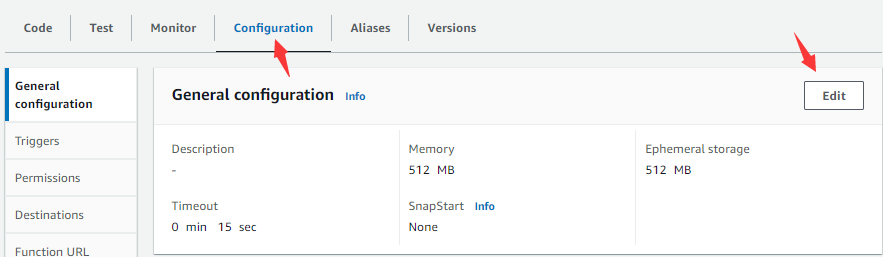
Click “Edit” button:
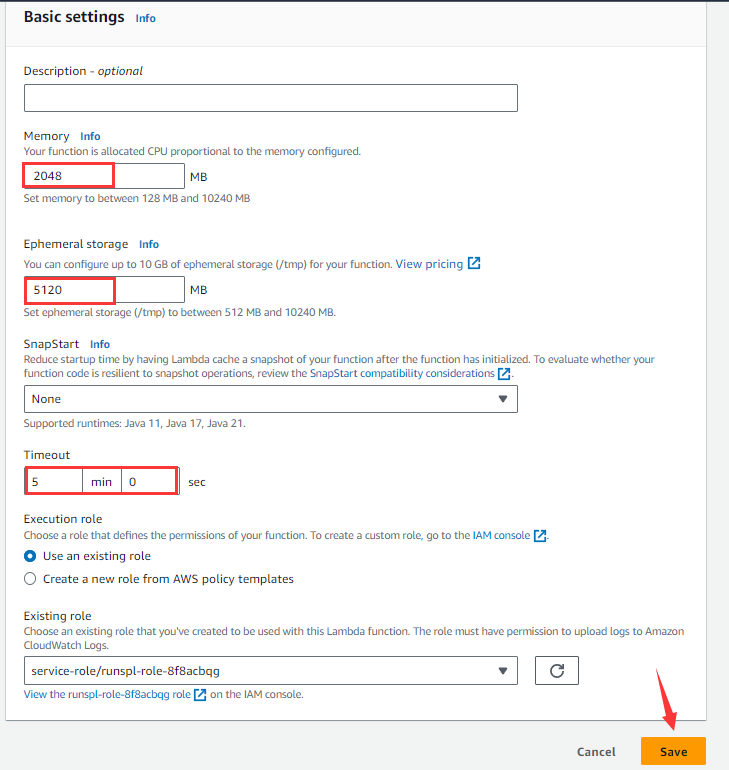
Edit Memory, Ephemeral storage and Timeout the function will use as needed (sizes of the first two items are related to the running costs AWS charges) and click “Save” button.
4. Calling functions
4.1 CALL method
Write a method to call runSPL in a Java application:
public static String callRunSpl( String splx, String paramJson ) throws Exception {
Region region = Region.CN_NORTH_1;
AwsCredentials c = AwsBasicCredentials.create( "AKIATA……IIIXO", "aYI3JBZOuR……3FvNhjDhoVQU0yN" );
StaticCredentialsProvider credential = StaticCredentialsProvider.create(c);
LambdaClient awsLambda = LambdaClient.builder().credentialsProvider(credential)
.httpClient(ApacheHttpClient.builder().socketTimeout( Duration.ofMinutes( 10 ) ).build()).region(region).build();
JSONObject jo = new JSONObject();
jo.put( "splx", splx );
if( paramJson != null ) jo.put( "parameters", paramJson );
SdkBytes payload = SdkBytes.fromUtf8String( jo.toString() );
InvokeRequest request = InvokeRequest.builder()
.functionName( " arn:aws:lambda:us-west-1:91……708:function:runspl " )
.payload(payload).build();
InvokeResponse res = awsLambda.invoke( request );
String result = res.payload().asUtf8String();
awsLambda.close();
return result;
}
In this method, the two parameters splx and paramJson respectively correspond to runSPL function’s parameters splx and parameters.
In line 2, region specifies the region where the AWS count works for creating the runSPL function. Line 3 specifies the accessKey and secretKey for accessing the count. Below shows where the name of function to be called in the functionName method comes from:
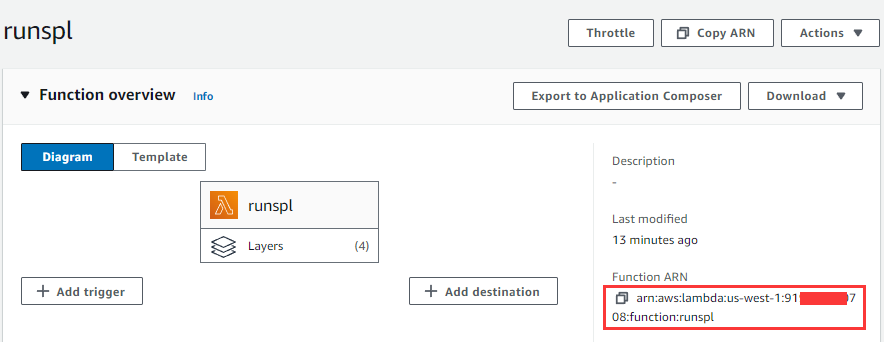
4.2 Use the MySQL table to compute in S3 script
Create a MySQL database instance in the Amazon RDS (Amazon Relational Database Service) cloud management system and then the TPC-H orders table; and import data to the table (skip the process of table creation and data import; use the similar way to access the other cloud databases via JDBC). Write the following script (rds-mysql.splx) to perform computations using data in the orders table:
| A | |
|---|---|
| 1 | =connect(“rds_mysql”) |
| 2 | =A1.cursor@m(“SELECT O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE FROM ORDERS where O_ORDERKEY<3000000”) |
| 3 | =A2.groups(year(O_ORDERDATE):year,O_ORDERSTATUS:status;sum(O_TOTALPRICE):amount) |
| 4 | =A1.close() |
| 5 | return A3 |
This script does not need parameters. Put it in the un-bucket103 storage bucket on S3 platform. Here is the statement for calling the runSPL function:
String result = callRunSpl("s3://un-bucket103/rds-mysql.splx", null);
It returns the following result:
[{"year":1992,"status":"F","amount":17215923334.65},
{"year":1993,"status":"F","amount":17081696141.77},
{"year":1994,"status":"F","amount":17240680768.02},
{"year":1995,"status":"F","amount":3312513758.50},
{"year":1995,"status":"O","amount":10389864034.13},
{"year":1995,"status":"P","amount":3559186116.08},
{"year":1996,"status":"O","amount":17300963945.13},
{"year":1997,"status":"O","amount":17076455987.72},
{"year":1998,"status":"O","amount":10169293696.22}]
4.3 Use a script in S3 to compute the composite table stored in S3
The composite table file orders.ctx is stored in un-bucket103 storage bucket on S3 platform. Write script s3_orders.splx to perform computations using data in the composite table:
| A | |
|---|---|
| 1 | =Qfile(“un-bucket103/orders.ctx”) |
| 2 | =date(startDate) |
| 3 | =date(endDate) |
| 4 | =A1.open().cursor@m(O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE;O_ORDERDATE>=A2 && O_ORDERDATE<=A3) |
| 5 | =A4.groups(year(O_ORDERDATE):year,O_ORDERSTATUS:status;sum(O_TOTALPRICE):amount) |
| 6 | return A5 |
Two parameters are defined in this script to represent the starting date and the ending date for the orders query:
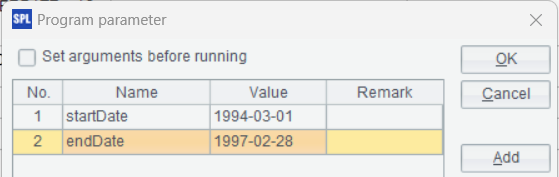
Place the script file in S3’s un-bucket103 storage bucket. Below is the statement of calling the runSPL function:
String result = callRunSpl("s3://un-bucket103/s3_orders.splx", "{\"startDate\":\"1995-01-01\",\"endDate\":\"1997-12-31\"}");
It returns the following result:
[{"year":1995,"status":"F","amount":6.614961429260002E9},
{"year":1995,"status":"O","amount":2.082205436133004E10},
{"year":1995,"status":"P","amount":7.109117393009993E9},
{"year":1996,"status":"O","amount":3.460936476086E10},
{"year":1997,"status":"O","amount":3.437363341303998E10}]
4.4 Use a local script to compute the local composite table
composite table file orders.ctx is located in the deployment package config.zip’s root directory on runsplConfig layer. Write the following script (orders.splx) to perform computations using data in this composite table:
| A | |
|---|---|
| 1 | =file(“/opt/orders.ctx”) |
| 2 | =date(startDate) |
| 3 | =date(endDate) |
| 4 | =A1.open().cursor@m(O_ORDERDATE, O_ORDERSTATUS, O_TOTALPRICE;O_ORDERDATE>=A2 && O_ORDERDATE<=A3) |
| 5 | =A4.groups(year(O_ORDERDATE):year,O_ORDERSTATUS:status;sum(O_TOTALPRICE):amount) |
| 6 | return A5 |
The zip deployment package will be decompressed to the /opt directory on the machine where runSPL function runs, so the composite table file path is /opt/orders.ctx. Except for using the file() function to access a local file, the script has the same code as the previous one.
This script file is also deployed in the zip package config.zip (Or it can be put on S3). Below is the statement of calling runSPL function:
String result = callRunSpl("/opt/orders.splx", "{\"startDate\":\"1995-01-01\",\"endDate\":\"1997-12-31\"}");
The statement returns the same result as the previous one.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version