

SPL Programming Exercise - Chapter 11 Big data
11.1 Big data and cursor
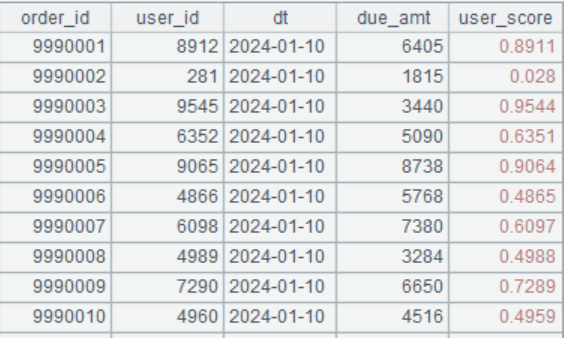
1. Program to generate a large file, as shown in the following figure. Require order_id to be ordered and unique, user_id to be random and have duplicates, dt to be ordered, due_amt to be random, and user_score to take a random value between 0 and 1. The same user corresponds to the same user_score.
The file is named “order_data.csv”
2. Create a cursor for the file “order_data.csv” generated from the previous question.
(1) Get 100 records from cursor
(2) Continue to retrieve 100 records from the cursor and observe the changes in order_id
(3) Continue to retrieve data from the cursor until there is a change in the dt value, and observe the data changes
3. Read “order_data.csv” as a cursor, count how many records are in the file, and sum due_amt
11.2 Functions on cursor
The data used in this section is “order_data.csv”.
1. Create a cursor using the file “order_data.csv”
(1) Get 100 records
(2) Skip 10000 records
(3) Get 100 more records
(4) Close cursor
2. Calculate the average and maximum values of due_amt
3. Count how many users there are
4. Query all user IDs
5. Count the number of orders and total amount for each user (due_amt)
6. Filter out orders with due_amt above 8000, and then calculate the number of orders and total amount(due_amt) by user
7. Use derive() to add the field user_level, divide users into different levels based on their scores, and write to “order_data.csv”. Users with a score exceeding 0.8 are classified as Grade A, those with a score between 0.6 and 0.8 are classified as Grade B, and those with a score below 0.6 are classified as Grade C.
8. For users of different levels, different discounts will be given. The discount rates for A, B, and C levels are 0.1, 0.05, and 0.02 respectively. Calculate the total amount and quantity of orders with a discount amount exceeding 500 on a monthly basis.
9. Add a discount amount field to orders with amounts above 5000 and write it into another file.
11.3 Ordered cursor
The data used in this section is “order_data.csv”
1. Group orders by date and get the first three groups of records
2. Calculate the order amount and number of orders for the user with the highest order amount per day
11.4 Big cursor
The data used in this section is “order_data.csv”
1. Sort the data in descending order by user_score, and get the first 100 pieces of data
2. View the top 3 orders with the highest order amount (due_amt)
3. Group by user_id and due_amt, count the number of orders in each group, and then filter out groups with orders greater than 3 to calculate the total amount
4. There is an employee information table employee.xlsx and an employee salary table salary.xlsx, with the primary key being Eid. Some of the data is as follows:
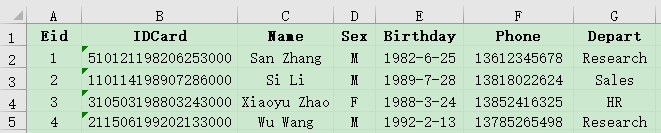
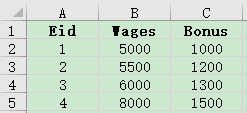
Please use a big join to concatenate the basic information and salary information of employees together.
Suggested answers
11.1 Big data and cursor
1.
| A | B | |
|---|---|---|
| 1 | for 0,999 | =10000.new(A1*10000+~:order_id,1+rand(10000):user_id,date(now())-1000+A1:dt,1+rand(10000):due_amt,(user_id-1)/10000:user_score) |
| 2 | =B1.select(rand()>=0.01) | |
| 3 | >file(“C:/Users/29636/Desktop/tmp/order_data.csv”).export@act(B2) |
2.
| A | |
|---|---|
| 1 | =file(“C:/Users/29636/Desktop/tmp/order_data.csv”).cursor@tc() |
| 2 | =A1.fetch(100) |
| 3 | =A1.fetch(100) |
| 4 | =A1.fetch(;dt) |
3.
| A | B | C | |
|---|---|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() | 0 | 0 |
| 2 | for A1,10000 | >B1+=A2.len() | |
| 3 | >C1+=A2.sum(due_amt) |
11.2 Functions on cursor
1.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.fetch(100) |
| 3 | =A1.skip(10000) |
| 4 | =A1.fetch(100) |
| 5 | >A1.close() |
2.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.total(avg(due_amt),max(due_amt)) |
3.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.total(icount(user_id)) |
4.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.groups(user_id) |
5.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.groups(user_id;count(~):order_count,sum(due_amt):sum_amt) |
6.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.select(due_amt>=8000) |
| 3 | =A2.groups(user_id;count(~):order_count,sum(due_amt):sum_amt) |
7.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.derive(if(user_score>=0.8:“A”,user_score<0.6:“C”;“B”):user_level) |
| 3 | =file(“C:/Users/29636/Desktop/tmp/order_data.csv”).export@tc(A2) |
8.
| A | |
|---|---|
| 1 | [A,B,C] |
| 2 | [0.1,0.05,0.02] |
| 3 | =A1.new(~:user_level,A2(#):discount).keys(user_level) |
| 4 | =file(“order_data.csv”).cursor@tc() |
| 5 | =A4.switch(user_level,A3).select(user_level.discount*due_amt>500) |
| 6 | =A5.groups(month@y(dt):ym;sum(due_amt):S,count(due_amt):C) |
9.
| A | |
|---|---|
| 1 | [A,B,C] |
| 2 | [0.1,0.05,0.02] |
| 3 | =A1.new(~:user_level,A2(#):discount).keys(user_level) |
| 4 | =file(“C:/Users/29636/Desktop/tmp/order_data.csv”).cursor@tc() |
| 5 | =A4.select(due_amt>5000) |
| 6 | =A5.join(user_level,A3,discount:dis_amt).run(dis_amt=due_amt*dis_amt) |
| 7 | >file(“C:/Users/29636/Desktop/tmp/data.csv”).export@ct(A6) |
11.3 Ordered cursor
1.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.group(dt) |
| 3 | =A2.fetch(3) |
2.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.group(dt) |
| 3 | =A2.(~.groups(user_id;sum(due_amt):S,count(due_amt):C).maxp@a(S)) |
| 4 | =A3.conj().fetch() |
11.4 Big cursor
1.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.sortx(-user_score) |
| 3 | =A2.fetch(1000) |
2.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.total(top(3;-due_amt)) |
3.
| A | |
|---|---|
| 1 | =file(“order_data.csv”).cursor@tc() |
| 2 | =A1.groupx(user_id,due_amt;count(1):C) |
| 3 | =A2.select(C>3).total(sum(C*due_amt)) |
4.
| A | |
|---|---|
| 1 | =file(“employee.xlsx”).cursor@t().sortx(Eid) |
| 2 | =file(“salary.xlsx”).cursor@t().sortx(Eid) |
| 3 | =joinx(A1:emp,Eid;A2:salary,Eid) |
| 4 | =A3.new(emp.Eid,emp.IDCard,emp.Name,emp.Sex,emp.Phone,emp.Depart,salary.Wages,salary.Bonus) |
| 5 | =A4.fetch(100) |
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc_SPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/cFTcUNs7
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version