

SPL Practices: Cross-database SQL Migration
Background
Applications may need to work based on different databases. Although the SQL syntax for various databases is generally consistent, differences still exist, which necessitates modifications to related SQL statements. Such modifications often require manual adjustments, which involve heavy workload and are error-prone.
Fully automating the SQL transformation is nearly impossible due to the varying functionalities of different databases.
However, upon closer examination, it becomes clear that most issues stem from differences in the syntax of SQL functions.
Especially for functions related to dates and strings, there isn’t a standard in the field, and each database has its own approach. For example, to convert string “2020-02-05” to a date, different databases have different syntax.
ORACLE:
select TO_DATE('2020-02-05', 'YYYY-MM-DD') from USER
SQL Server:
select CONVERT(varchar(100), '2020-02-05', 23) from USER
MySQL:
select DATE_FORMAT('2020-02-05','%Y-%m-%d') from USER
If an application needs to switch between different databases, the SQL statement must be rewritten.
SPL solution
SPL offers a SQL conversion function for this scenario to convert a certain standard SQL to statements in different databases, thus enabling seamless SQL migration during database switch.
In sql.sqltranslate(dbtype) function, sql at the beginning is the SQL statement to be translated, and parameter dbtype is the database type. Involved functions need to be defined in SPL simple SQL, undefined ones will not be translated. Find the list of defined functions and database types sqltranslate() in esProc Function Reference.
SQL migration in SPL IDE
Let’s first try performing the SQL migration in SPL’s IDE, and convert SQL statement SELECT EID, NAME, BIRTHDAY, ADDDAYS(BIRTHDAY,10) DAY10 FROM EMP to syntax in different databases.
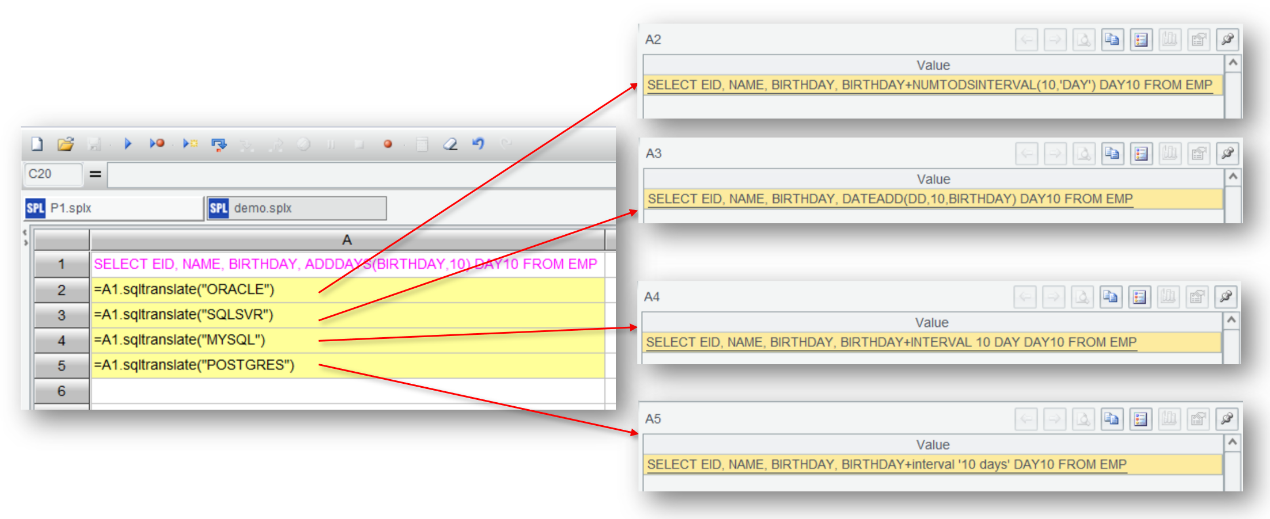
We can see that the ADDDAYS function is translated to different databases’ syntax, and cross-database SQL migration is successfully finished.
Here are more examples.
Add 10 to the month
SELECT EID, NAME, BIRTHDAY, ADDMONTHS(BIRTHDAY,10) DAY10 FROM EMP
Translate this SQL statement to syntax in different databases:
ORACLE:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+NUMTOYMINTERVAL(10,'MONTH') DAY10 FROM EMP
SQLSVR:
SELECT EID, NAME, BIRTHDAY, DATEADD(MM,10,BIRTHDAY) DAY10 FROM EMP
DB2:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+10 MONTHS DAY10 FROM EMP
MYSQL:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+INTERVAL 10 MONTH DAY10 FROM EMP
POSTGRES:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+interval '10 months' DAY10 FROM EMP
TERADATA:
ADDMONTHS function has significantly different forms across different databases. SQL Server uses DATEADD function, while MySQL and PostgreSQL directly add 10. And Oracle combines the two ways in its statement.
Get quarter
SELECT EID,AREA,QUARTER(ORDERDATE) QUA, AMOUNT FROM ORDERS
Convert the statement to:
ORACLE:
SELECT EID,AREA,FLOOR((EXTRACT(MONTH FROM ORDERDATE)+2)/3) QUA, AMOUNT FROM ORDERS
SQLSVR:
SELECT EID,AREA,DATEPART(QQ,ORDERDATE) QUA, AMOUNT FROM ORDERS
POSTGRES:
SELECT EID,AREA,EXTRACT(QUARTER FROM ORDERDATE) QUA, AMOUNT FROM ORDERS
TERADATA:
SELECT EID,AREA,TD_QUARTER_OF_YEAR(ORDERDATE) QUA, AMOUNT FROM ORDERS
The QUARTER function is available in various databases, but there are significant differences in the names and parameters used for the function.
Type conversion
SELECT EID, NAME, DATETOCHAR(BIRTHDAY) FROM EMP
Convert the statement to:
ORACLE:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
SQLSVR:
SELECT EID, NAME, CONVERT(CHAR,BIRTHDAY,120) FROM EMP
DB2:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
MYSQL:
SELECT EID, NAME, DATE_FORMAT(BIRTHDAY, '%Y-%m-%d %H:%i:%S) FROM EMP
POSTGRES:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
TERADATA:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
There are also different type conversion functions, with significant variations in function names and formats across databases.
These differences can all be addressed using SPL’s sqltranslate() function.
Function definition and extension
The database types and function definitions supported by SPL are located in the dictionary file /com/scudata/dm/sql/function.xml in the release package esproc-bin. jar.
<?xml version="1.0" encoding="utf-8"?>
<STANDARD>
<FUNCTIONS type="FixParam">
<FUNCTION name="ADDDAYS" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1+NUMTODSINTERVAL(?2,'DAY')"></INFO>
<INFO dbtype="SQLSVR" value="DATEADD(DD,?2,?1)"></INFO>
<INFO dbtype="DB2" value="?1+?2 DAYS"></INFO>
<INFO dbtype="MYSQL" value="?1+INTERVAL ?2 DAY"></INFO>
<INFO dbtype="HSQL" value="DATEADD('dd', ?2, ?1)"></INFO>
<INFO dbtype="TERADATA" value="?1+CAST(?2 AS INTERVAL DAY)"></INFO>
<INFO dbtype="POSTGRES" value="?1+interval '?2 days'"></INFO>
<INFO dbtype="ESPROC" value="elapse(?1,?2)"></INFO>
</FUNCTION>
</FUNCTIONS>
</STANDARD>
The FUNCTIONS node represents a function group, type is the function group type, and FixParam represents a function group with a fixed number of parameters. The FUNCTION node represents a simple SQL function, where name is the function name, paramcount is the number of parameters, and value is the default value to which the function will be translated; an empty value string indicates that there is no need to translate. The INFO node represents a database, dbtype is the database name (an empty string indicates SPL simple SQL), and value is the corresponding value to which the SQL function is translated to syntax in this database. In the value, ? or ?1 represents value of the first parameter in the function, ?2 represents the second parameter value, and so on. When value in INFO is an empty string, use the value specified in parent node FUNCTION.
During translation, if there is no INFO node definition for the specified database under the FUNCTION node, this function remains unchanged and will not be translated.
SPL defines many functions, but not all, in funtion.xml. In practice, you may encounter new functions and can add them on your own.
For example, to calculate the number of days between between two dates, we can add a FUNCTION node, define function name as DATEDIFF, and configure syntax of different databases in the INFO node.
<FUNCTION name="DATEDIFF" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1-?2"></INFO>
<INFO dbtype="SQLSVR" value="DATEDIFF(day,?1,?2)"></INFO>
<INFO dbtype="MYSQL" value="DATEDIFF(?1,?2)"></INFO>
<INFO dbtype="POSTGRES" value="?1-?2"></INFO>
<INFO dbtype="ESPROC" value="interval(?2,?1)"></INFO>
</FUNCTION>
Similarly, to add support for other databases, simply add the INFO node information and configure the new databases. For instance, we want to add support for SQLite here to implement the above translation of date difference.
<FUNCTION name="DATEDIFF" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1-?2"></INFO>
<INFO dbtype="SQLSVR" value="DATEDIFF(day,?1,?2)"></INFO>
<INFO dbtype="MYSQL" value="DATEDIFF(?1,?2)"></INFO>
<INFO dbtype="POSTGRES" value="?1-?2"></INFO>
<INFO dbtype="ESPROC" value="interval(?2,?1)"></INFO>
<INFO dbtype="SQLite" value="JULIANDAY(?1) - JULIANDAY(?2)"></INFO>
</FUNCTION>
With a fixed number of parameters
The earlier function examples featured a fixed number of parameters, but there are scenarios where the number of parameters cannot be predetermined, such as in string concatenation, CASE WHEN statements, and retrieving the first non-null value from multiple parameters.
SPL also supports a dynamic number of parameters by configuring FUNCTIONS node’s type value as AnyParam, which is any number of parameters.
<FUNCTIONS type="AnyParam">
<FUNCTION classname="com.scudata.dm.sql.simple.Case" name="case">
<INFO dbtype="ESPROC" classname="com.scudata.dm.sql.simple.Case"></INFO>
</FUNCTION>
<FUNCTION classname="com.scudata.dm.sql.simple.Coalesce" name="coalesce">
<INFO dbtype="ESPROC" classname="com.scudata.dm.sql.simple.Coalesce"></INFO>
</FUNCTION>
<FUNCTION classname="com.scudata.dm.sql.simple.Concat" name="concat">
<INFO dbtype="ESPROC" classname="com.scudata.dm.sql.simple.Concat"></INFO>
</FUNCTION>
</FUNCTIONS>
We need to create Java classes for defined functions in each database. For example, to add support for Oracle’s string function CONCAT, we can write the following code:
public class Concat implements IFunction
{
public String getFormula(String[] params)
{
StringBuffer sb = new StringBuffer();
for(int i = 0, len = params.length; i < len; i++) {
if(params[i].isEmpty()) {
throw new RQException("Concat function parameter cannot be empty");
}
if(i > 0) {
sb.append(" || ");
}
sb.append(params[i]);
}
return sb.toString();
}
}
Compile this piece of code, and place it in the /com/scudata/dm/sql/oracle path within the esproc-bin.jar.
Then configure the translation class corresponding to Oracle in funtion.xml.
<FUNCTIONS type="AnyParam">
<FUNCTION classname="com.scudata.dm.sql.simple.Case" name="case">
<INFO dbtype="ESPROC" classname="com.scudata.dm.sql.simple.Case"></INFO>
</FUNCTION>
<FUNCTION classname="com.scudata.dm.sql.simple.Coalesce" name="coalesce">
<INFO dbtype="ESPROC" classname="com.scudata.dm.sql.simple.Coalesce"></INFO>
</FUNCTION>
<FUNCTION classname="com.scudata.dm.sql.simple.Concat" name="concat">
<INFO dbtype="ESPROC" classname="com.scudata.dm.sql.simple.Concat"></INFO>
<INFO dbtype="ORACLE" classname="com.scudata.dm.sql.oracle.Concat"></INFO>**
</FUNCTION>
</FUNCTIONS>
Restart IDE after modifying the jar file. Let’s try it.
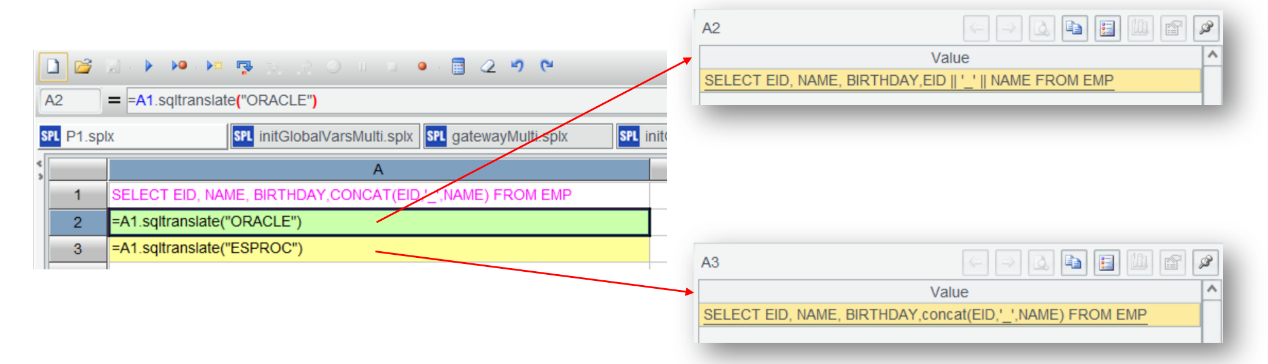
It can be seen that when the conversion is done, double vertical bars are used to concatenate the three parameters in Oracle, while the lowercase concat is used to do the same thing when the target database is esProc.
As of now, we have learned how to use and configure SPL’s SQL translation function, and how to add functions and databases to it, including situations with an uncertain number of parameters.
Work in applications
Next, let’s look at how to integrate SPL into an application.
It is very simple to integrate SPL into an application. Just import these esproc-bin-xxxx.jar and icu4j-60.3.jar in [installation directory]\esProc\lib into the application, and then copy raqsoftConfig.xml, which is in [installation directory]\esProc\config, to the application’s class path.
raqsoftConfig.xml is the core SPL configuration file, whose name cannot be changed. It will be needed in subsequent data source and gateway configurations.
With a single database
Let’s first look at the scenario where the application only has a single database.
Usage 1- Only use SQL translation
The simplest way to use SPL’s SQL translation function in applications is using sqltranslate() to translate the SQL statement into the syntax of the target database and execute it.
The API for translating SQL statements in SPL is com.scudata.dm.sql.SQLUtil.translate function, and it can be used directly to translate a SQL statement.
String sql = "select name, birthday, adddays(birthday,10) day10 from emp";
sql = com.scudata.dm.sql.SQLUtil.translate(sql, "MYSQL");
However, it should be noted that the SPL official recommendation is to use the JDBC interface instead of the API directly. Yet, writing a few lines of code to connect to JDBC solely for a string conversion can be cumbersome, so we opted to use the API directly.
Additionally, we aim to make SQL migration as transparent as possible. Aside from the initial rewrite, there is no need to modify an recompile the code when the database is changed in the future – just maintain the configuration file. Therefore, we store the database type in the configuration file.
For example, we can create a database type configuration file called dbconfig.properties to specify the database type, such as MYSQL.
Content of dbconfig.properties:
database.type=MYSQL
Then, we can encapsulate a translation method that calls SPL’s API to implement SQL translation.
public static String translateSQL(String sql) {
String dbType = null;
try (InputStream input = SQLTranslator.class.getClassLoader().getResourceAsStream("dbconfig.properties")) {
Properties prop = new Properties();
if (input == null) {
System.out.println("Sorry, unable to find dbconfig.properties");
return null;
}
prop.load(input);
dbType = prop.getProperty("database.type");
} catch (Exception ex) {
ex.printStackTrace();
}
return SQLUtil.translate(sql, dbType);
}
Pass in the SQL statement to the main program, which calls the SQL translation. The following code, including parameter setup, SQL execution, and obtaining the result set, remains unchanged. In fact, the only addition in the main program is one statement sql = translateSQL.
public static void main(String[] args) {
……
String sql = “SELECT name, birthday, adddays(birthday,10) day10 “
+ “ FROM emp where dept=? and salary>?” ;
sql = translateSQL(sql);
pstmt.setString(1, "Sales");
pstmt.setDouble(2, 50000);
……
}
Usage 2 – Execute SQL transparently
The previous method requires an additional translation step for each SQL invocation. If there are many SQL statements, the changes to the original program can be substantial. Additionally, it utilizes interfaces that are not officially recommended, which may pose a risk of future incompatibility.
To overcome these drawbacks, we can adopt a more transparent approach that translates SQL and executes it to obtain the result set directly within SPL.
SPL supports standard JDBC. As long as the database driver and URL are switched to SPL’s, the rest of the code can remain completely unchanged, eliminating the need for encapsulation methods or explicit translation.
public static void main(String[] args) {
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
String sql = "SELECT orderid, employeeid, adddays(orderdate,10) day10,amount "
+ "FROM orders WHERE employeeid > ? AND amount > ?";
PreparedStatement st = conn.prepareStatement(sql);
st.setObject(1,"506");
st.setObject(2,9900);
ResultSet rs = st.executeQuery();
while (rs.next()) {
String employeeid = rs.getString("employeeid");
System.out.print(employeeid+",");
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
So, how is SQL translation implemented? It seems a bit magical.
The key is SPL’s JDBC gateway. We configure a SPL script in advance, and all SQL statements to be executed in JDBC will be handed over to this script for processing and execution. That is to say, the translation and execution of SQL are both done in the script.
To use the JDBC gateway, we need to configure a SPL script in the JDBC node of raqsoftConfig.xml, such as gateway.splx configured here.
<JDBC>
<load>Runtime,Server</load>
<gateway>gateway.splx</gateway>
</JDBC>
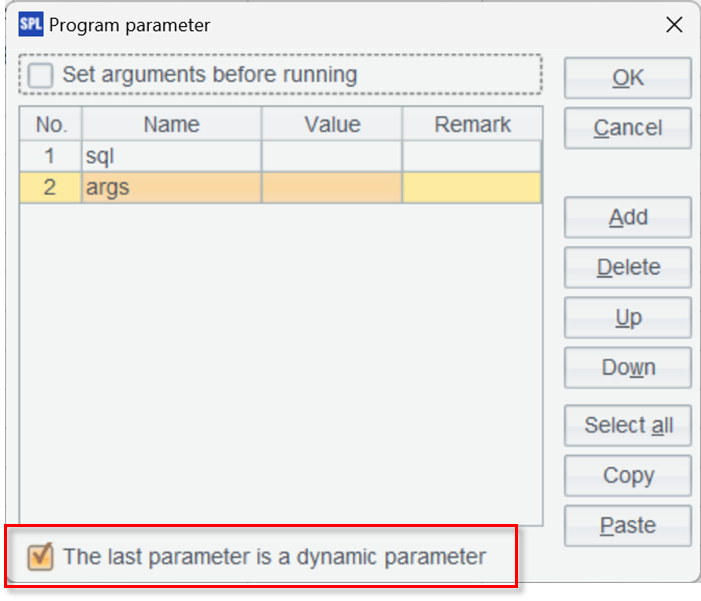
The gateway script requires two parameters – one is sql for receiving SQL statements and the other is args for receiving parameters, which are those passed from JDBC to SQL, used in the SQL statement,.
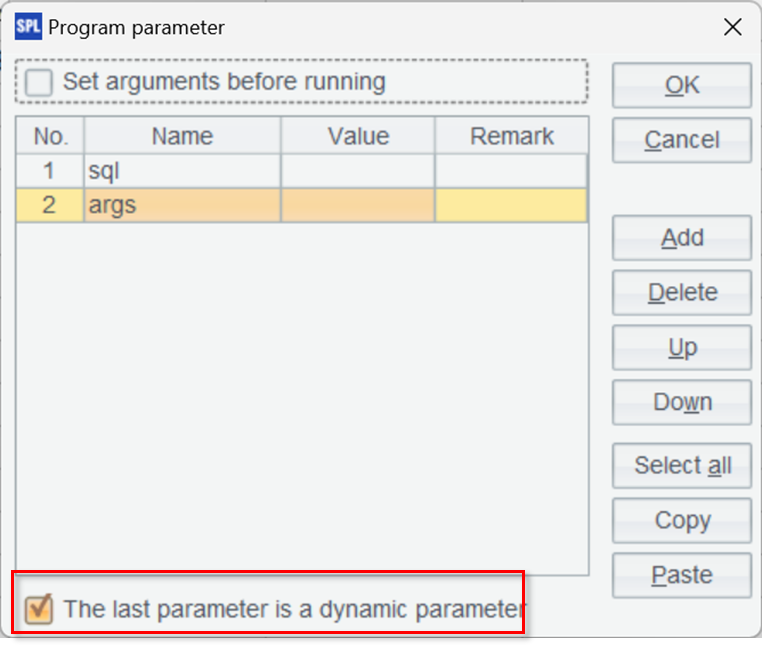
The option below “The last parameter is a dynamic parameter” needs to be checked in order to receive multiple parameters of the SQL statement.
Here is the script:
| A | B | |
|---|---|---|
| 1 | if !ifv(dbName) | >call(“initGlobalVars.splx”) |
| 2 | =sql=trim(sql).sqltranslate(dbType) | |
| 3 | =argsN=args.len() | =(“sql “argsN.(“args(”/~/”)”)).concat@c() |
| 4 | =connect(dbName) | |
| 5 | if pos@hc(sql,“select”) | return A4.query@x(${B3}) |
| 6 | else | =A4.execute(${B3}) |
| 7 | >A4.close() |
A1 judges whether the dbName variable exists. If it does not exist, call the initialization script initGlobalVars.splx in B1:
| A | |
|---|---|
| 1 | >env(dbType,file(“dbconfig.properties”).property(“database.type”)) |
| 2 | >env(dbName,file(“dbconfig.properties”).property(“database.name”)) |
This script reads the data source name and database type from the configuration file and places them in global variables dbType and dbName using the env() function.
Here is the content of configuration file dbconfig.properties:
database.type=MYSQL
database.name=MYDATASOURCE
A2 translates the SQL statement. We are already familiar with the method.
A3 gets the number of parameters. B3 concatenates the parameters into a string. For example, when there are two parameters, the result of B3 is like this.
A4 connects to the data source, which is configured in raqsoftConfig.xml file by simply adding the corresponding data source connection information in the DB node. Multiple data sources can be configured sequentially.
<DB name="MYDATASOURCE">
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mydb?useCursorFetch=true"></property>
<property name="driver" value="com.mysql.jdbc.Driver"></property>
<property name="type" value="10"></property>
<property name="user" value="root"></property>
<property name="password" value="root"></property>
<property name="batchSize" value="0"></property>
<property name="autoConnect" value="false"></property>
<property name="useSchema" value="false"></property>
<property name="addTilde" value="false"></property>
<property name="caseSentence" value="false"></property>
</DB>
A5 judges whether it is a select statement. We need to translate and execute all SQL statements, but DQL and DML statements have different execution methods and return values, so they need to be processed separately.
If it is a select statement, B5 uses the db.query() function to query data and obtain results, where @x closes the database connection after querying. SPL macro is used here, and the statement replaced with macro is like this.
A6 requires the use of the db.execute() function to execute SQL statements for non-select statements.
The overall script is not very complex, and future modifications to the script do not need to restart the application, as SPL uses interpreted execution mode and supports hot-swapping.
Through this gateway script, DML statements such as update can also be executed.
public static void main(String[] args) {
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
String sql = "update orders set customername = ? where orderid = ? ";
PreparedStatement st = conn.prepareStatement(sql);
st.setObject(1,"PTCAG001");
st.setObject(2,"1");
st.executeUpdate();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
We will execute the update statement in the program and see that it will also be translated into the corresponding statement in the target database, and the update is successful. This means all SQL statements can be seamlessly migrated.
With multiple databases
How should we handle situations where the application involves multiple databases?
Usage 1- Only use SQL translation
Let’s first look at the translation-only usage.
We still need to maintain the data source name and type in the configuration file. Add the following to dbsconfig.properties:
database.oracleds.type=ORACLE
database.mysqlds.type=MYSQL
database.pgds.type=POSTGRESQL
The middle part of the string before the equal sign represents the data source name, such as oracleds, while the part on the right of it indicates the data source type, such as ORACLE. Because there are multiple databases, we need to search for types according to data source names.
Write the translation method, search for the type according to data source name, load the configuration file to obtain properties, and translate SQL statements:
public static String translateSQL(String sql, String dataSourceName) {
try (InputStream input = SQLTranslator.class.getClassLoader().getResourceAsStream("dbsconfig.properties")) {
Properties prop = new Properties();
if (input == null) {
System.out.println("Sorry, unable to find dbsconfig.properties");
return null;
}
prop.load(input);
String dbType = prop.getProperty("database." + dataSourceName.toLowerCase() + ".type");
if (dbType == null) {
throw new RuntimeException("Data source " + dataSourceName + " not configured in the configuration file.");
}
return SQLUtil.translate(sql, dbType);
} catch (Exception ex) {
ex.printStackTrace();
return null;
}
}
This process is similar to what was previously mentioned, so we will not repeat it here.
When the main program works, the SQL statement along with the data source name, which can be mysqlDS or other sources, are passed to it, and the SQL is translated, followed then by parameter setting, SQL statement execution and obtaining result sets, all of which are the same as those in the original program.
public static void main(String[] args) {
String sql = "SELECT orderid, employeeid, adddays(orderdate,10) day10,amount "
+ "FROM orders WHERE employeeid > ? AND amount > ?";
String dataSourceName = "mysqlds";
String translatedSQL = translateSQL(sql, dataSourceName);
System.out.println("Translated SQL: " + translatedSQL);
……
}
Usage 2 – Translate SPL script and execute SQL
We discussed the advantages and disadvantages of translation-only earlier. Now let’s explore the use of SPL gateway for translating and executing SQL statements.
public static void main(String[] args) {
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
String mysqlDsName = "mysqlds";
Connection mysqlConn = DriverManager.getConnection(url);
String setDS = "setds "+ mysqlDsName;
PreparedStatement setst = mysqlConn.prepareStatement(setDS);
setst.execute();
String sql = "SELECT orderid, employeeid, adddays(orderdate,10) day10,amount "
+ "FROM orders WHERE employeeid > ? AND amount > ?";
PreparedStatement st = mysqlConn.prepareStatement(sql);
st.setObject(1, "506");
st.setObject(2, 9900);
ResultSet rs = st.executeQuery();
while (rs.next()) {
String employeeid = rs.getString("employeeid");
System.out.print(employeeid + ",");
}
} catch (Exception e) {
throw new RuntimeException(e);
}
Here we establish connections to different data sources separate, with an additional step to set the data source name. Data source parsing is handled in the gateway script, while the rest of the SQL execution remains fully consistent with the original program.
The parameters in the gateway script are completely same as those in the previous single database gateway script, where parameter sql receives SQL statements and parameters args receives SQL parameters.
Below is the content of gateway script gateway.splx:
| A | B | |
|---|---|---|
| 1 | if !ifv(dbs) | >call(“initGlobalVarsMulti.splx”) |
| 2 | =sql=trim(sql) | |
| 3 | if pos@hc(sql,“setds”) | >env@j(dsName,lower(trim(mid(sql,7)))) |
| 4 | >env@j(dbType,dbs.select(name==“database.”+dsName+“.type”).value) | |
| 5 | return | |
| 6 | =sql=sql.sqltranslate(dbType) | |
| 7 | =argsN=args.len() | =(“sql “argsN.(“args(”/~/”)”)).concat@c() |
| 8 | =connect(dsName) | |
| 9 | if pos@hc(sql,“select”) | return A8.query@x(${B7}) |
| 10 | else | >A8.execute(${B7}) |
| 11 | >A8.close() |
The gateway script for dealing with multiple databases also includes the data source name setting process.
The initialization script initGlobalVarsMulti.splx invoked by B1 reads the configuration file:
| A | |
|---|---|
| 1 | >env(dbs,file(“dbsconfig.properties”).property()) |
And gets the following result:

A3 receives a parameter from the program to set the data source, which is specified as “setds mysqlds”. If it starts with setds, B3 will assign the data source name to the job variable dsName. The job variable’s scope is the same Connection. Next, all SQL statements within this data source can be run directly. Similarly, B4 searches for the database type according to the data source list dbs and assigns it to the job variable dbType.
The script from A6 onward is the same as the single database version, and we will not explain it again.
This gateway script can still handle all SQL statements and allows for seamless migration.
The above outlines everything we need to know about SQL migration in SPL. With SPL, database switching does not require modifying code any more, and a seamless migration can be achieved.
Of course, SPL’s capabilities extend well beyond that. It also supports parallel execution of SQL data retrieval, facilitates cross-database queries, enables mixed computation between databases and non-database sources, and leverages its computing power to optimize SQL performance. We will introduce these topics in future discussions one by one.
SPL is now open-source. You can obtain the source code from GitHub in https://github.com/SPLWare/esProc.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version