

SPL Reporting: Cross-Database Migratable Reports
Background
Compared with a general transaction processing system (TP), SQL in reports uses more computing functions and involves more complicated logics, hence the application relies more on the database language. The report development may have to deal with switchover from one database to another. Though different databases use similar SQL, there are differences in syntactic details. SQL of reports needs to be modified to adapt to different types of database. The work is heavy and error-prone.
100% auto-transformation of SQL statements is infeasible because different functionalities between databases make it difficult to directly migrate certain complicated computations. However, some examinations show that most incompatibilities are caused by different syntax of same functions, particularly functions related to date and string handling, for which there is no industry standard and databases have their own rules.
For example, to convert string “2020-02-05” to date, different databases have different syntax.
#ORACLE:
select TO_DATE('2020-02-05', 'YYYY-MM-DD') from USER
#SQL Server:
select CONVERT(varchar(100), '2020-02-05', 23) from USER
#MySQL:
select DATE_FORMAT('2020-02-05','%Y-%m-%d') from USER
If a report involves such SQL functions needs to switch between different databases, the SQL statement must be rewritten.
SPL solution
SPL offers a SQL conversion function for handling cross-database SQL migration scenarios. It can convert any SPL-defined standard SQL statements to dialects of different databases, thus enabling SQL migration between databases and avoiding re-writing SQL during database switch.
sql.sqltranslate(dbtype) function implements SPL’s SQL translation functionality. In the function, sql at the beginning is the SQL statement to be translated, and parameter “dbtype” is the database type. Involved functions need to be defined in SPL’s standard SQL (called simple SQL in SPL), undefined ones will not be translated. Find the list of defined functions and database types in esProc Function Reference’s sqltranslate().
Here are relationships between SPL and reports and databases: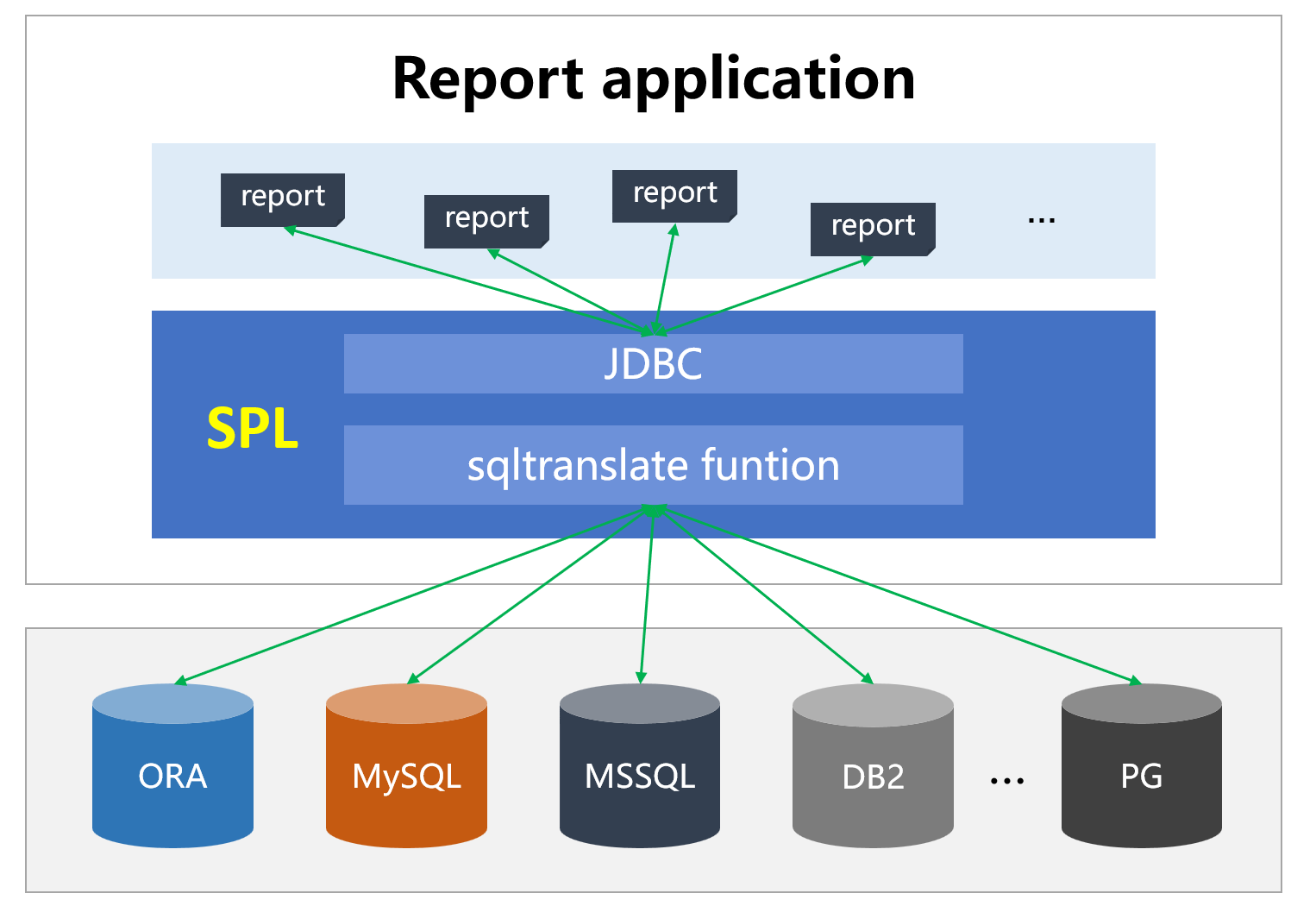
SPL can be embedded into the reporting application to work. The report connects to SPL through the standard JDBC and sends a standard SQL statement to SPL; and the latter uses conversion function sqltranslate to convert it to syntax of the target database, execute it, and returns result to the report to present.
Let’s first try performing the SQL migration in SPL IDE – convert SQL statement
SELECT EID, NAME, BIRTHDAY, ADDDAYS(BIRTHDAY,10) DAY10 FROM EMP
to syntax of different databases.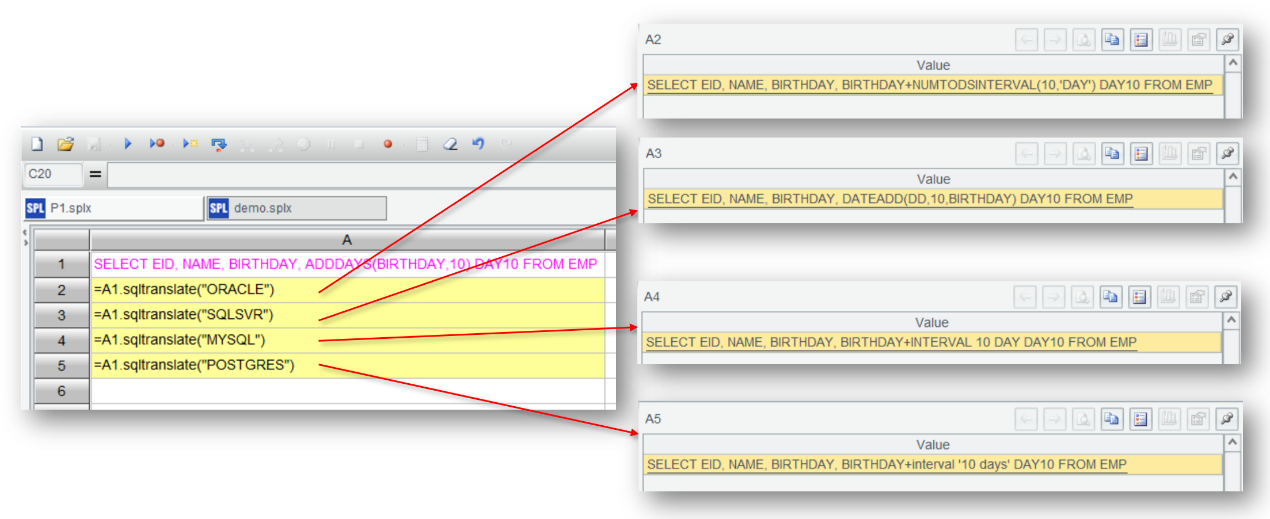
We can see that the ADDDAYS function is translated to syntax of different databases, and cross-database SQL migration is successfully achieved.
Here are more examples.
To compute order amount in each quarter, we have the following SQL statement:
SELECT QUARTER(order_date) AS quarter, SUM(total_amount) AS total_sales
FROM orders
GROUP BY QUARTER(order_date);
And use sqltranslate()to convert it to syntax of different databases:
#ORACLE:
SELECT TO_CHAR(order_date, 'Q') AS quarter, SUM(total_amount) AS total_sales
FROM orders
GROUP BY TO_CHAR(order_date, 'Q');
#SQLSVR:
SELECT DATEPART(QUARTER, order_date) AS quarter, SUM(total_amount) AS total_sales
FROM orders
GROUP BY DATEPART(QUARTER, order_date);
#MYSQL:
SELECT QUARTER(order_date) AS quarter, SUM(total_amount) AS total_sales FROM orders GROUP BY QUARTER(order_date);
#POSTGRES:
SELECT EXTRACT(QUARTER FROM order_date) AS quarter, SUM(total_amount) AS total_sales FROM orders GROUP BY EXTRACT(QUARTER FROM order_date);
For each year, find the month when the most orders are placed and count the orders:
SELECT YEAR(order_date) AS year, MONTH(order_date) AS month, COUNT(*) AS order_count
FROM orders
GROUP BY YEAR(order_date), MONTH(order_date)
ORDER BY YEAR(order_date), order_count DESC;
Then convert it to syntax of different databases:
#ORACLE:
SELECT EXTRACT(YEAR FROM order_date) AS year, EXTRACT(MONTH FROM order_date) AS month, COUNT(*) AS order_count
FROM orders
GROUP BY EXTRACT(YEAR FROM order_date), EXTRACT(MONTH FROM order_date)
ORDER BY year, order_count DESC;
#SQLSVR:
SELECT YEAR(order_date) AS year, MONTH(order_date) AS month, COUNT(*) AS order_count
FROM orders
GROUP BY YEAR(order_date), MONTH(order_date)
ORDER BY year, order_count DESC;
#MYSQL:
SELECT YEAR(order_date) AS year, MONTH(order_date) AS month, COUNT(*) AS order_count
FROM orders
GROUP BY YEAR(order_date), MONTH(order_date)
ORDER BY YEAR(order_date), order_count DESC;
#POSTGRES:
SELECT EXTRACT(YEAR FROM order_date) AS year, EXTRACT(MONTH FROM order_date) AS month, COUNT(*) AS order_count
FROM orders
GROUP BY EXTRACT(YEAR FROM order_date), EXTRACT(MONTH FROM order_date)
ORDER BY year, order_count DESC;
Compute total order amount in the past 30 days and count the number of orders:
SELECT SUM(total_amount) AS total_sales, COUNT(*) AS total_orders
FROM orders
WHERE order_date >= ADDDAYS(NOW(),-30);
Then convert it to syntax of different databases:
#ORACLE:
SELECT SUM(total_amount) AS total_sales, COUNT(*) AS total_orders
FROM orders
WHERE order_date >= SYSDATE - 30;
#SQLSVR:
SELECT SUM(total_amount) AS total_sales, COUNT(*) AS total_orders
FROM orders
WHERE order_date >= DATEADD(DAY, -30, GETDATE());
#MYSQL:
SELECT SUM(total_amount) AS total_sales, COUNT(*) AS total_orders
FROM orders
WHERE order_date >= DATEADD(DAY, -30, GETDATE());
#POSTGRES:
SELECT SUM(total_amount) AS total_sales, COUNT(*) AS total_orders
FROM orders
WHERE order_date >= NOW() - INTERVAL '30 DAYS';
We will stop here and won’t give more examples. All those syntactic differences can be bridged through SPL’s sqltranslate() function.
Integrate with the reporting application
It is very simple to integrate SPL into the reporting application. Just import SPL’s esproc-bin-xxxx.jar and icu4j-60.3.jar (generally located in [installation directory]\esProc\lib)into the application, and then copy raqsoftConfig.xml (also located in [installation directory]\esProc\lib) to the application’s class path.
raqsoftConfig.xml is the core SPL configuration file, whose name cannot be changed. It will be needed in subsequent data source and gateway configurations.
From the standpoint of the reporting application, SPL is a logical database that can smoothing out the database difference at the low level. The report connects to SPL via JDBC. For example, below is the SPL data source connection configured in the reporting application:
<Context>
<Resource name="jdbc/esproc"
auth="Container"
type="javax.sql.DataSource"
maxTotal="100"
maxIdle="30"
maxWaitMillis="10000"
username=""
password=" "
driverClassName=" com.esproc.jdbc.InternalDriver "
url=" jdbc:esproc:local://?jobVars=dbType:MYSQL,dbName:MYDATASOURCE ">
</Resource>
</Context>
Note that two parameters are specified in the JDBC URL – MYSQL for dbType (database type) and MYDATASOURCE for dbName (data source name). Both parameters are stored in the SPL job variable.
Now we can perform the report query based on different databases. Without the need to modify the report for database switch, report migration between databases becomes seamless. Below is the standard SQL statement for the previous example:
SELECT QUARTER(order_date) AS quarter, SUM(total_amount) AS total_sales
FROM orders
GROUP BY QUARTER(order_date);
By configuring the connection parameter dbType as ORACLE, the SQL statement the database executes is:
SELECT TO_CHAR(order_date, 'Q') AS quarter, SUM(total_amount) AS total_sales
FROM orders
GROUP BY TO_CHAR(order_date, 'Q');
When the connection parameter dbType is specified as MYSQL, the SQL statement the database executes is:
SELECT QUARTER(order_date) AS quarter, SUM(total_amount) AS total_sales
FROM orders
GROUP BY QUARTER(order_date);
It seems a bit magical, because no specific database information is configured and the sqltranslate() function previously mentioned isn’t used, then how is SQL translation implemented?
The key is SPL JDBC gateway. We configure a SPL script in advance, and all statements (including SQL statement) received by SPL JDBC will be handed over to this script for processing. That is to say, both the translation and execution of SQL statements are performed in the script.
To use the JDBC gateway, we need to configure a SPL script in the JDBC node of raqsoftConfig.xml, such as gateway.splx configured here.
<JDBC>
<load>Runtime,Server</load>
<gateway>gateway.splx</gateway>
</JDBC>
The gateway script requires two parameters – one is sql for receiving the SQL statement and the other is args for receiving parameters, which are those passed from JDBC to SQL, used in the SQL statement.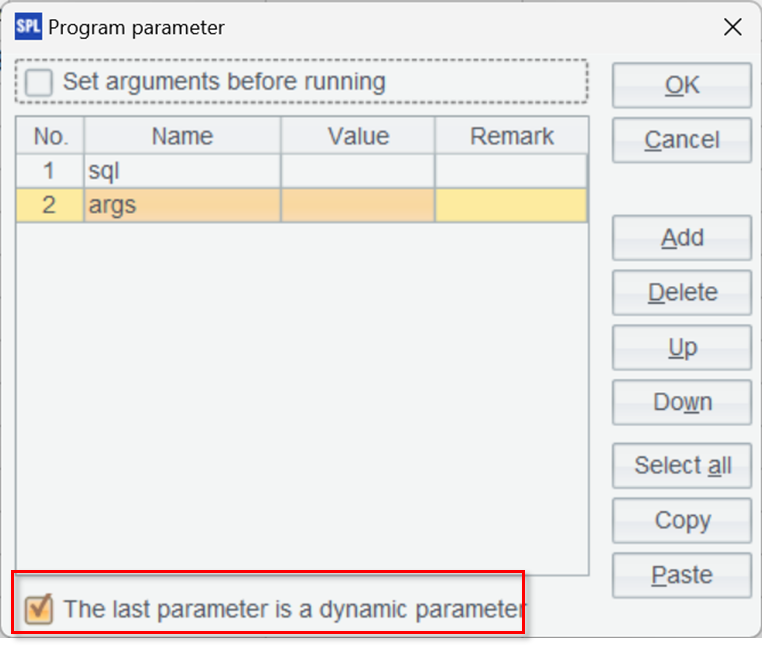
The option “The last parameter is a dynamic parameter” needs to be checked in order to receive multiple parameters of the SQL statement.
The gateway script is simple. There are only several lines:
A |
B |
|
1 |
=sql=trim(sql).sqltranslate(dbType) |
|
2 |
=argsN=args.len() |
=("sql"|argsN.("args("/~/")")).concat@c() |
3 |
=connect(dbName) |
return A3.query@x(${B2}) |
A1 uses sqltranslate to translate the SQL statement. Here dbType is the corresponding parameter previously configured in JDBC URL. Its value can be directly used here.
A2 gets the number of parameters, and B2 concatenates parameters into a string. For example, we have the following statement to query specified order records:
select * from orders where orderdate>=? and orderdate <=?
It uses 2 parameters (whose values are 20240101 and 20241231 respectively). Below is B2’s result:
sql,args(1),args(2)
A3 connects to the data source, whose dbName, as the above dbType, is also configured in JDBC URL. The data source is configured in raqsoftConfig.xml file by simply adding the corresponding data source connection information in the DB node. Multiple data sources can be configured sequentially.
<DB name="MYDATASOURCE">
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mydb?useCursorFetch=true"></property>
<property name="driver" value="com.mysql.jdbc.Driver"></property>
<property name="type" value="10"></property>
<property name="user" value="root"></property>
<property name="password" value="root"></property>
<property name="batchSize" value="0"></property>
<property name="autoConnect" value="false"></property>
<property name="useSchema" value="false"></property>
<property name="addTilde" value="false"></property>
<property name="caseSentence" value="false"></property>
</DB>
B3 uses db.query() function to query data,obtain result and return to the report. @x closes the database connection after querying is finished. SPL macro is used here, and the statement replaced with macro is this:
A4.query@x(sql,args(1),args(2))
The statement finally executed after parsing is:
A4.query@x(“select * from orders where orderdate>=? and orderdate <=?” ,20240101,20241231)
It gets the result and returns to the report.
The script is simple, and future modifications to it do not need to restart the application, as SPL uses interpreted execution mode and supports hot-swapping.
Sometimes multiple databases are involved in the report query. And we need to configure multiple SPL data sources for the report application to correspond to the multiple databases. For example:
<Context>
<Resource name="jdbc/esproc"
auth="Container"
type="javax.sql.DataSource"
maxTotal="100"
maxIdle="30"
maxWaitMillis="10000"
username=""
password=" "
driverClassName=" com.esproc.jdbc.InternalDriver "
url=" jdbc:esproc:local://? jobVars=dbType:MYSQL,dbName:mysqlds">
</Resource>
<Resource name="jdbc/esproc"
auth="Container"
type="javax.sql.DataSource"
maxTotal="100"
maxIdle="30"
maxWaitMillis="10000"
username=""
password=" "
driverClassName=" com.esproc.jdbc.InternalDriver "
url=" jdbc:esproc:local://? jobVars=dbType:ORACLE,dbName:oracleds ">
</Resource>
</Context>
Then the SQL translation can be performed through the above gateway script.
Note that database connections should be configured in raqsoftConfig.xml, as shown below:
<DB name="mysqlds">
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mydb?useCursorFetch=true"></property>
<property name="driver" value="com.mysql.jdbc.Driver"></property>
…
</DB>
<DB name="oracleds">
<property name="url" value="jdbc:oracle:thin:@192.168.0.108:1521:orcl"></property>
<property name="driver" value="oracle.jdbc.driver.OracleDriver"></property>
…
</DB>
Function definition and extension
SPL’s function definition and extension functionality is managed through function.xml file. The file is located in /com/scudata/dm/sql/ path in esproc-bin.jar. SPL has defined a lot of functions, but they do not cover all possible scenarios. In the real-world practices, the file can be manually extended if new functions are needed or new databases need to be supported.
<?xml version="1.0" encoding="utf-8"?>
<STANDARD>
<FUNCTIONS type="FixParam">
<FUNCTION name="ADDDAYS" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1+NUMTODSINTERVAL(?2,'DAY')"></INFO>
<INFO dbtype="SQLSVR" value="DATEADD(DD,?2,?1)"></INFO>
<INFO dbtype="DB2" value="?1+?2 DAYS"></INFO>
<INFO dbtype="MYSQL" value="?1+INTERVAL ?2 DAY"></INFO>
<INFO dbtype="HSQL" value="DATEADD('dd', ?2, ?1)"></INFO>
<INFO dbtype="TERADATA" value="?1+CAST(?2 AS INTERVAL DAY)"></INFO>
<INFO dbtype="POSTGRES" value="?1+interval '?2 days'"></INFO>
<INFO dbtype="ESPROC" value="elapse(?1,?2)"></INFO>
</FUNCTION>
</FUNCTIONS>
</STANDARD>
The FUNCTIONS node represents a function group; “type” is the function group type, and “FixParam” represents a function group with a fixed number of parameters. The FUNCTION node represents a simple SQL function, where “name” is the function name, “paramcount” is the number of parameters, and “value” is the default value to which the function will be translated; an empty value string indicates that there is no need to translate. The INFO node represents a database; “dbtype” is the database name (an empty string indicates SPL simple SQL), and “value” is the corresponding value to which the SQL function is translated to syntax in this database. In the value, ? or ?1 represents value of the first parameter in the function, ?2 represents the second parameter value, and so on. When “value” in INFO is an empty string, use the “value” specified in parent node FUNCTION.
During translation, if there is no INFO node definition for the specified database under the FUNCTION node, this function remains unchanged and will not be translated.
Function extension
For example, to add a function to calculate the number of days between two dates, we can add a FUNCTION node, define function name as DATEDIFF, and configure syntax of different databases in the INFO node.
<FUNCTION name="DATEDIFF" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1-?2"></INFO>
<INFO dbtype="SQLSVR" value="DATEDIFF(day,?1,?2)"></INFO>
<INFO dbtype="MYSQL" value="DATEDIFF(?1,?2)"></INFO>
<INFO dbtype="POSTGRES" value="?1-?2"></INFO>
<INFO dbtype="ESPROC" value="interval(?2,?1)"></INFO>
</FUNCTION>
Similarly, to add support for other databases, simply add the INFO node information and configure the new databases. For example, we want to add support for SQLite here to implement the above translation of date difference.
<FUNCTION name="DATEDIFF" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1-?2"></INFO>
<INFO dbtype="SQLSVR" value="DATEDIFF(day,?1,?2)"></INFO>
<INFO dbtype="MYSQL" value="DATEDIFF(?1,?2)"></INFO>
<INFO dbtype="POSTGRES" value="?1-?2"></INFO>
<INFO dbtype="ESPROC" value="interval(?2,?1)"></INFO>
<INFO dbtype="SQLite" value="JULIANDAY(?1) - JULIANDAY(?2)"></INFO>
</FUNCTION>
With an unfixed number of parameters
The pervious function examples featured a fixed number of parameters, but there are scenarios where the number of parameters cannot be predetermined, such as in string concatenation, CASE WHEN statements, and retrieving the first non-null value from multiple parameters.
SPL also supports a dynamic number of parameters by configuring FUNCTIONS node’s type value as AnyParam, which is any number of parameters.
<FUNCTIONS type="AnyParam">
<FUNCTION name="coalesce">
<INFO dbtype="ESPROC" script='"ifn(" + ?.concat@c() +")"'/>
</FUNCTION>
<FUNCTION name="concat">
<INFO dbtype="ESPROC" script=' "concat("+ ?.concat@c() +")" '/>
</FUNCTION>
</FUNCTIONS>
We just need to add database type and the corresponding translation script (SPL syntax) under FUNCTION node. To add the support of Oracle for string function CONCAT, for example, add the following content under <FUNCTION name="concat">:
<INFO dbtype="ORACLE" script=' "("+ ?.concat(" || ") +")" '/>
And the configuration is finished.
Later when database type is ORCALE, SQL statement
SELECT EID,NAME,BIRTHDAY,concat(EID,"_",NAME) FROM EMP
will be translated as:
SELECT EID,NAME,BIRTHDAY,(EID || "_" || NAME) FROM EMP
And it will be translated to the following syntax when the database type is ESPROC:
SELECT EID,NAME,BIRTHDAY,concat(EID,"_",NAME) FROM EMP
With SPL, reports can be conveniently migrated between any databases without the need of modification.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version