

This Is Probably the Most Lightweight Columnar Storage Technology
Columnar storage is an important technique to improve data processing & analysis. If a data table has a large number of columns but the processing/analysis only involves a very small number of them, columnar storage lets you read the target columns only. This helps reduce disk accesses and boost performance. One column generally contains data of the same type. Sometimes it even has values that are close to each other. By storing such data in order, it can be compressed more efficiently.
But setting up a column-oriented data warehouse for use in real-world applications is too complicated. All the commonly used lightweight databases, such as MySQL, do not support columnar storage. Most of the time the technology is used by large-scale MPP databases. Hadoop also provides columnar file formats, such as Parquet and ORC, but their work environment (Hadoop or Spark) is complicated, which means a too heavy framework. Though the application is open-source and free, the overall costs are very high.
Well, is there a lightweight columnar storage technology that does not depend on a heavy framework?
The open-source computing engine esProc’s ctx file is such a lightweight columnar storage technology. esProc offers simple and efficient programming language SPL for perform operations on ctx files.
SPL can dump data coming from any sources to a ctx file that uses the columnar storage, or vice versa.
Take a csv file and a database table as examples:
A |
B |
|
1 |
/csv to ctx |
|
2 |
=T@c("orders.csv").sortx(O_ORDERKEY) |
|
3 |
=file("orders.ctx").create@y(#O_ORDERKEY,O_CUSTKEY,O_ORDERSTATUS,O_TOTALPRICE,O_ORDERDATE,O_ORDERPRIORITY,O_CLERK,O_SHIPPRIORITY,O_COMMENT) |
|
4 |
=A3.append(A2) |
=A3.close() |
5 |
/ctx to csv |
|
6 |
=file("orders_new.csv").export@tc(T@c("orders.ctx")) |
|
7 |
/DB to ctx |
|
8 |
=connect("demo") |
|
9 |
=A8.cursor("select ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE from sales order by ORDERID") |
|
10 |
=file("sales.ctx").create@y(#ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE) |
|
11 |
=A10.append(A9) |
=A10.close() |
12 |
/ctx to DB |
|
13 |
=A8.execute(T@c("sales.ctx"),"insert into sales (ORDERID,CLIENT,SELLERID,AMOUNT,ORDERDATE) values(?,?,?,?,?)",#1,#2,#3,#4,#5) |
|
14 |
>A8.close() |
|
Compared with row-wise files, columnar files work in a bit more complicated way. We need to first fix the data structure and create a corresponding index zone before writing data to it. But SPL has the special ability to produce very simple code.
Columnar storage is usually used to store a large volume of data. That’s why our sample code uses cursor. The ctx file can make good use of the cursor to read and write data in the stream style.
SPL also gives powerful computational ability to ctx files. A ctx file can be parallelly processed in segments:
A |
B |
|
1 |
=file("orders.ctx").open().cursor@m(O_ORDERKEY,O_CUSTKEY;between(O_ORDERDATE,date(1996,1,1):date(1996,1,31))) |
/Filtering |
2 |
=file("orders.ctx").open().cursor@m(O_ORDERDATE,O_TOTALPRICE).groups(O_ORDERDATE;sum(O_TOTALPRICE):all,max(sum(O_TOTALPRICE)):max) |
/Grouping & aggregation |
3 |
=file("orders.ctx").open().cursor@m(O_CUSTKEY;[2,3,5,8].contain(O_CUSTKEY)).total(icount(O_CUSTKEY)) |
/Count distinct |
4 |
=file("orders.ctx").open().cursor@m(O_ORDERKEY,O_TOTALPRICE;![20,31,55,86].contain(O_CUSTKEY)).total(top(-10;O_TOTALPRICE)) |
/TOP N |
5 |
= T("customer.btx").keys(C_CUSTKEY) |
/Foreign-key based association |
6 |
=file("orders.ctx").open().cursor@m(O_ORDERKEY,O_CUSTKEY,O_TOTALPRICE).switch(O_CUSTKEY,A5) |
|
7 |
=file("customer.ctx").open().cursor@m(C_CUSTKEY,C_ACCTBAL) |
/Primary-key based association |
8 |
=file("customer_info.ctx").open().cursor(CI_CUSTKEY,FUND;;A7) |
|
9 |
=joinx(A7:c, C_CUSTKEY;A8:ci,CI_CUSTKEY) |
|
10 |
=A9.new(c.C_ACCTBAL+ci.FUND:newValue) |
cursor() function works with @m option to split a ctx file into multiple segments and perform multithreaded processing. This is simple and easy to use.
In the code, the defined file object file("orders.ctx") can be used repeatedly. The cursor, however, only can compute once, and a new one needs to be defined for the next computation.
Dividing data into segments is the prerequisite of performing parallel processing. The commonly used block-based columnar storage can improve performance only when there is a large volume of data, generally 10bn records in a single table and about 100GB in size. The parallel processing improves performance little if there is only a relatively small volume of data. Yet the ctx file offers innovative double increment segmentation technique. The technique enables to divide a very small amount of data into reasonable segments while more data is continuously appended to it, and ensures performance boost for parallel processing.
In addition to the double increment segmentation technique, ctx also provides many built-in high-performance storage solutions. One instance is the unique sequence-numberization mechanism, which overcomes the difficulty in creating indexes on column-stored data. Another is the order-based storage mechanism, which stores equal values continuously within the same column to enhance columnar compression efficiency.
According to the comparison test, the ctx’s read performance is almost one time faster than ORC’s and far better than Parquet’s:
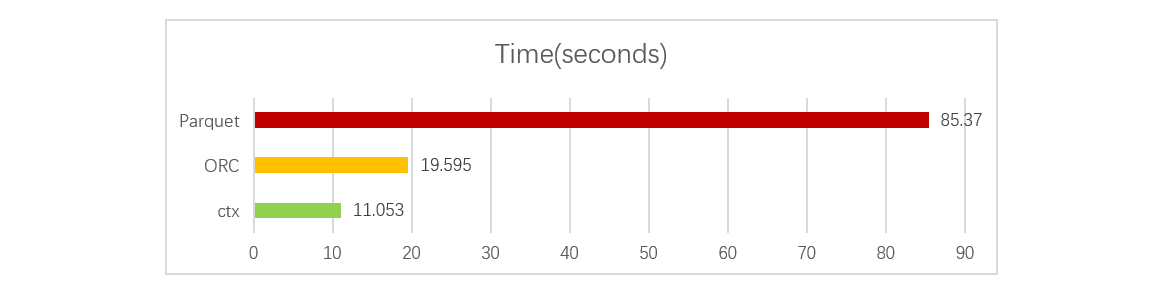
Detailed test process and conclusion can be found in Comparison of esProc composite table, ORC, Parquet in RaqForum.
esProc SPL is very lightweight. Its plug-and-play IDE does not require environment configurations, which is mandatory with Hadoop, as well as the cluster:

esProc supplies standard JDBC driver to enable easy integration of ctx in the application. Just put esProc’s core jar files and configuration file in the Java application’s class path, and the ctx file and the finished SPL script (such as compute.splx) in the configured directory. Then we can call the SPL script:
…
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
st =con.prepareCall("call computeCtx()");
st.execute();
ResultSet set = st.getResultSet();
…
For the same logic, SPL needs far less code than Java. We can implement various complex ctx-related computations using the SPL script. The front-end application only needs to receive the computing result and present it.
The esProc core jar file is less than 100 MB, which is surpassingly small.
The ctx file is particularly suitable to work in reporting applications for caching the report data. This can achieve the computing performance equal to that of a special columnar data warehouse, and does not require the installation and configuration of any heavyweight application like MPP or Hadoop/Spark.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version