

This Is Probably the Most Lightweight Alternative Technology to Logical Data Warehouses
Contemporary business analytics applications (such as common reporting applications) often need to extract data from different systems. The data are stored in different locations, have different formats, use different storage formats, and are updated at different intervals. They can be sales data in CRM, financial data in the accounting system, inventory information in ERP, and even external data in the cloud. These data sources are like jigsaw puzzle pieces, which have different shapes and contain different types of information. And how to put them together appropriately to fit for data analytics has been a constant challenge in terms of efficiency and flexibility.
The logical data warehouse is OK, but…
Logical data warehouses are often used to unite multiple data sources. They bring together data from disparate sources, put them in an integrated, “virtualized” platform, and allow users to perform queries and report analyses through a single view. The transparency abstracts differences between the low-level sources, enabling users to query and analyze data from any sources in the consistent way. Even if the data sources are changed in the future, the application needs only slight or little changes, which is another embodiment of transparency. Moreover, logical data warehouses do not have the latency caused by data transformation and loading – which traditional data warehouses have – and achieve higher data realtimeness.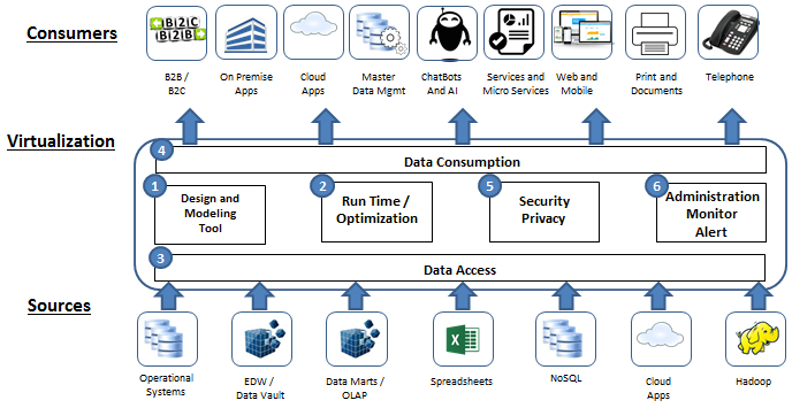 However, logical data warehouse are too heavy. Now all mainstream logical data warehouses use the cluster architecture. Usually there are a lot of nodes, and the resource cost is very high. Also, their configurations are complicated, the setup is not easy, and maintenance costs are high in order to make them run smoothly. As a result, the overall framework becomes heavy. Building a logical data warehouse is far complicated than the application itself. It’s reasonable to use them on a large organization’s data platform. But if you build one just for like report analysis application, the effort is somewhat not worth the cost.
However, logical data warehouse are too heavy. Now all mainstream logical data warehouses use the cluster architecture. Usually there are a lot of nodes, and the resource cost is very high. Also, their configurations are complicated, the setup is not easy, and maintenance costs are high in order to make them run smoothly. As a result, the overall framework becomes heavy. Building a logical data warehouse is far complicated than the application itself. It’s reasonable to use them on a large organization’s data platform. But if you build one just for like report analysis application, the effort is somewhat not worth the cost.
SPL’s lightweight solution
If you think the effort of building a heavy logical data warehouse only to handle a mixed-source computation task is not worth the cost, you do want to know esProc SPL. It gives wings to the analytics system so that cumbersome framework and expensive maintenance are avoided, and the system responds fast and adjusts to dynamic needs flexibly. 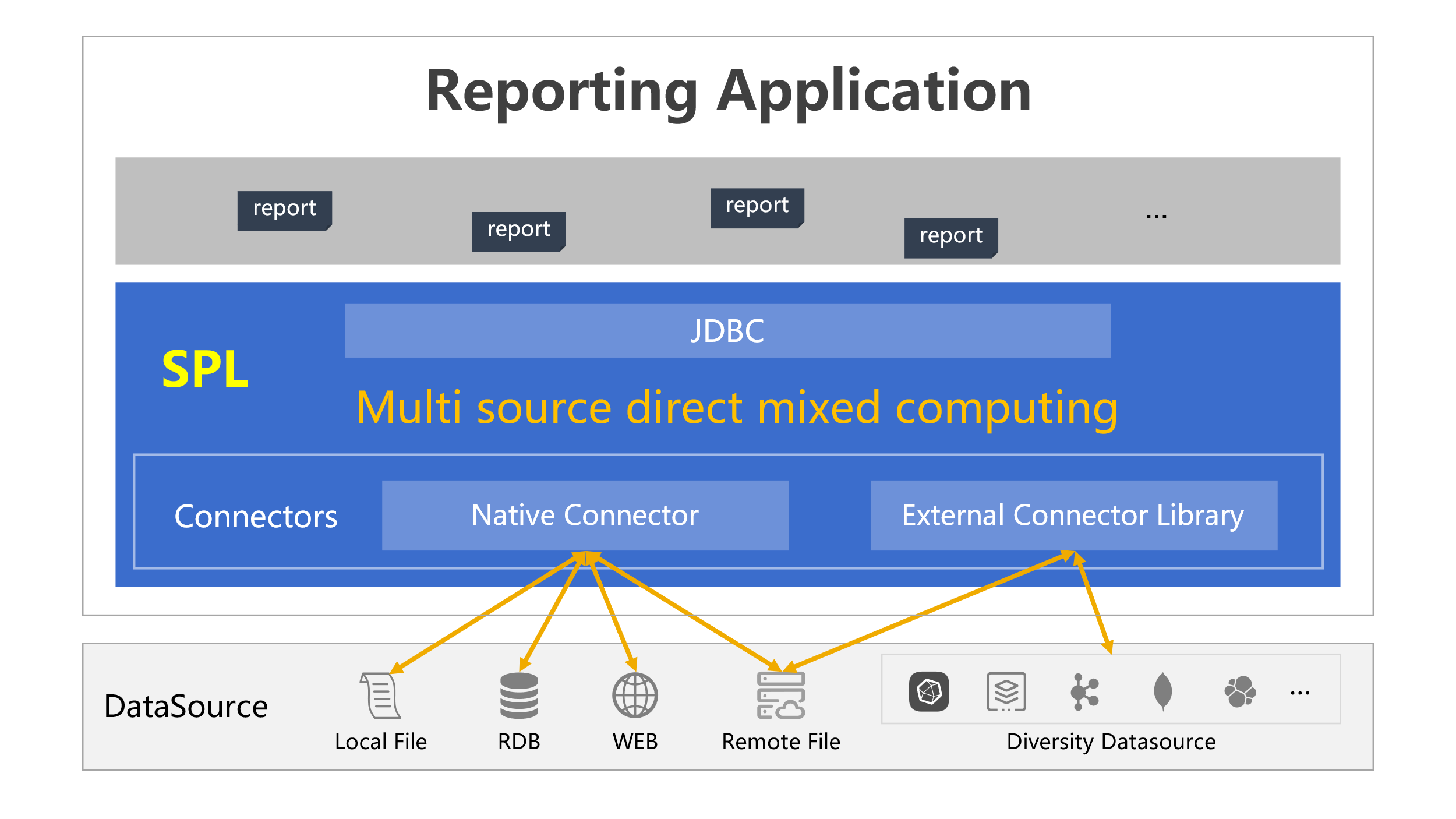
SPL offers two core data objects, table sequence and cursor, to compute all data regardless of source and size, without the need of defining complicated metadata mapping. The data access process becomes simple, and the ability to handle mixed-source computations follows naturally.
More importantly, SPL is far more lightweight than logical data warehouses. It gets rid of the complex virtualization process and the heavy database system as well. To use SPL, you just need to import its jar files to the target application. It particularly fits the reporting applications, where you can directly process data from multiple sources through a script. Since SPL can be deployed along with the application, it does not need an extra cluster environment. This helps save a large amount of hardware resources, and makes operation and maintenance simple.
SPL is lightweight also in terms of configurations and uses. To integrate with an application, just import SPL’s two jar files to the application and copy the core configuration file. No other complicated setup is needed.
SPL has been encapsulated as a standard JDBC driver. Configure data source of SPL JDBC and the report can then access SPL.
For example, to perform the mixed computation across MongoDB and MySQL:
Prepare the SPL script (orderAmount.splx):
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE()- INTERVAL 1 MONTH") |
3 |
=mongo_open("mongodb://127.0.0.1:27017/raqdb") |
4 |
=mongo_shell@d(A3, "{'find':'products', 'filter': { 'category': {'$in': ['Tablets', 'Wearables', 'Audio'] } }}” ) |
5 |
=A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
6 |
=A5.groups(category;sum(price*quantity):amount) |
7 |
return A6 |
Then, as you do with the stored procedure, call the script from the application:
call orderAmount()
The whole process does not involve system setup and complicated configurations. Only a few simple steps are enough to finish the mixed-source computation. Find detailed integration and SPL uses in SPL Practices Series: SPL Reporting: Make Lightweight, Mixed-Source Reports without Logical Data Warehouse.
SPL supports a vast range of data sources, including SQL-based RDBs, NoSQL databases, Webservices, JSON, file system, and so on, making it easy to access any type of data sources without the need to transform data to the consistent format. 
Some of the data sources SPL supports
At the same time, SPL provides the extended interface, through which users can add more data sources as needed.
While logical data warehouses are almost completely transparent, SPL scripts are not transparent to data sources. They need to be modified when data sources are changed. This is because SPL offers different retrieval methods (interfaces) for different data sources in order to make good use of each source’s strength. In the above script, for example, SPL performs data filtering and join using SQL and MongoDB Shell respectively. This utilizes each data source’s strengths and helps achieve high realtimeness as well.
Since SPL boasts a complete set computing abilities, the data source switch only requires modifying the retrieval logic while the main computing logic and the SPL-based application remains unchanged. This makes a high degree of transparency.

Only change the SPL retrieval logic when data source is changed
In summary, SPL offers a simple and lightweight solution, which lets users deal with the challenging mixed-source computing scenarios with complete gear. This, plus the other merits, including concise syntax and easy-to-use interface, qualifies SPL as the standard tool for handling mixed-source computation scenarios, especially the ones involving reporting applications.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version