

Train your own model and revitalize historical data
In the DT era, data as an asset is increasingly valued, and various industries have accumulated a lot of historical data. However, the precipitated data is only a resource, and only when used can the value of the data be released. It is particularly important to revitalize data assets and fully leverage the value of historical data.
Data mining is naturally an essential means. For example, businesses can mine users’ interests through their historical consuming behaviors, so as to develop more accurate sales strategies; In industrial production, by mining historical production process data of products, production processes can be optimized; In the medical industry, by exploring the history of patients’ symptoms and medication usage, doctors can diagnose diseases more quickly and accurately. In short, as long as there is historical data, data mining can be used to develop the value in the data and revitalize data assets.
However, data mining is a complex matter. Firstly, historical data may be multi-source data from different systems or may be raw transaction flow data, and some ETL work needs to be done to organize it into a wide table to model. This part is not difficult but very cumbersome. If there is a suitable tool, the efficiency will be much higher.
Secondly, the modeling part of data mining is very difficult and usually requires the participation of data scientists, which is difficult for ordinary people to master. Moreover, the modeling process is not overnight. Even data scientists need to repeatedly debug and optimize based on their own knowledge and experience to build a model, which can be as short as a few days or as long as several months, time-consuming and laborious. So automatic modeling technology gradually emerged. Automatic modeling is to integrate the experience of data scientists into software products. The software completes a series of processes such as data preprocessing, model selection, parameter adjustment, model evaluation, etc. On the one hand, automatic modeling can lower the threshold of data mining, and ordinary programmers and rookies can also build good models. On the other hand, it can also improve modeling efficiency. Models that originally took a few days or months can be shortened to a few hours or days. Using automatic modeling technology, ordinary programmers or business personnel can use their historical data at any time to train their own models, fully explore the value of the data, and revitalize historical data.
So, are there any useful tools that can enable ordinary people to train their own models with the help of automatic modeling technology?
Of course there is, using SPL.
SPL is an open source, lightweight tool with a very professional automatic modeling library called Ymodel. In SPL, automatic modeling can be achieved through simple function invocations. For programmers, there is no need to learn how to preprocess data, nor do they need to learn various complex algorithm principles and parameter applications. As long as they have a conceptual understanding of data mining, they can build high-quality models. For data scientists, there is no need to immerse themselves in repeatedly processing data and debugging models, greatly reducing manual workload and improves work efficiency.
For example, a financial company has some historical data, including user basic information, asset information, historical loan records, loan product information, etc. Based on this data, a model can be built to predict user default risk. The SPL code is as follows:
| A | B | |
|---|---|---|
| 1 | =file(“train.csv”).import@qtc() | |
| 2 | =ym_env() | Initialize environment |
| 3 | =ym_model(A2,A1) | Load modeling data |
| 4 | =ym_target(A3,“y”) | Set prediction target |
| 5 | =ym_build_model(A3) | Perform modeling |
View model performance:
| A | B | |
|---|---|---|
| … | ||
| 6 | =ym_present(A5) | View model information |
| 7 | =ym_performance(A5) | View model performance |
| 8 | =ym_importance(A5) | View variable importance |
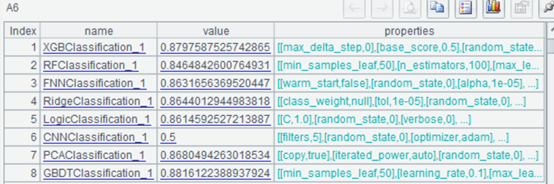
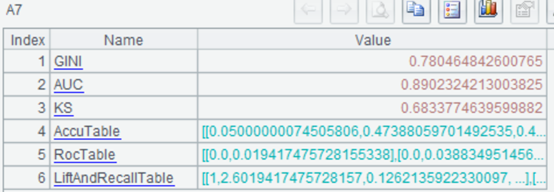
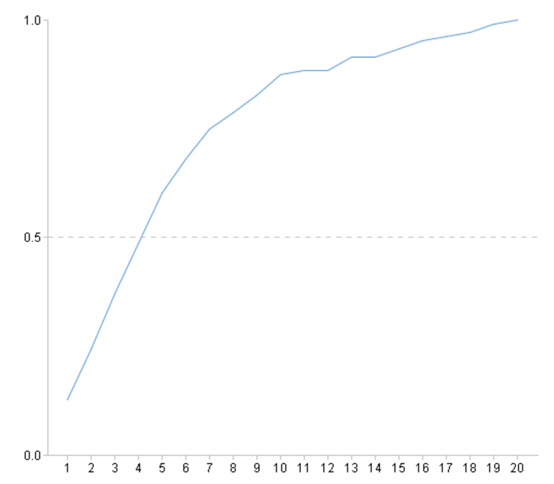
Use the model to predict the probability of user default:
| A | ||
|---|---|---|
| … | ||
| 9 | =ym_predict(A5,A1) | Execute predictions |
| 10 | =ym_result(A9) | Obtain prediction results |

The higher the probability value of the predicted results, the higher the risk of default. Therefore, business personnel can quickly identify high-risk customers based on the predicted results and take corresponding measures to reduce bad debt losses in a timely manner. For high-quality customers with low risk, marketing can be strengthened to increase customer stickiness and create more value.
With SPL, the modeling and prediction process can be implemented by simply invoking a few functions. For users, there is no complex data preprocessing, no obscure algorithm principles and parameters, and all can be implemented in SPL, which can be used by both beginners and rookies for modeling.
SPL modeling is not only easy to operate and convenient to use, but also does not require a large amount of data, and thousands of pieces of data can build a model. A small model can be built in minutes. Users can easily use their historical data to train models, fully explore the value of historical data, revitalize historical data, and make it truly an asset, rather than just a resource lying in the warehouse.
For a more complete data mining process, you can refer to: Data mining, modeling and prediction in SPL
In addition, SPL itself is a tool that is good at structured data computing. It has rich computing functions and excellent big data computing ability. It is also suitable for data preparation (ETL). For details, please refer to The ‘Artificial’ in Artificial Intelligence .
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version