

The 'Artificial' in Artificial Intelligence
Since AlphaGo won, artificial intelligence has become very popular, and the emergence of ChatGPT has pushed the popularity of artificial intelligence to a new level. However, when people talk about “intelligence”, they rarely focus on “artificial”. It seems that with the help of artificial intelligence, everything can be automated. In fact, behind this intelligence lies a large amount of “manual labor” and a considerable amount of things that cannot be automated.
The labor here is mainly reflected in two aspects:
1. Data preparation
The basic methods of modern artificial intelligence technology, or machine learning, are not much different from those of data mining more than N years ago, and a large amount of data is still fed to computers for training models. Once the models are generated, they can be used for automated processing, which looks like there is intelligence.
However, machine learning projects used for practical business do not have the ability to generate data for training like AlphaGo (in fact, the previous versions of AlphaGo also used a large number of existing game records), and must use actual data to train the model. ChatGPT also uses a large amount of books and internet data to train the model. The models trained with different data are completely different, and the quality of the data seriously affects the effectiveness of the model.
However, the actual data is diverse and scattered across various application systems and even different websites. It is not an easy task to organize them for algorithm use. Machine learning often requires well-organized wide table data, which also requires concatenation of associated data from various application systems; And the data encoding rules of each system may be different, which still needs to be unified first; Some data is still in the original text (log) form, and structured information needs to be extracted beforehand; Not to mention the data extracted from the internet; …
Experienced programmers know that in an artificial intelligence project, the time spent on data preparation accounts for approximately 70% -80%, which means that the vast majority of the workload is spent before training the model.
This is actually what we often refer to as ETL work. These things seem to have little technical content, as if they can be done by any programmer, and people are not very concerned about them, but the cost is extremely high.
2. Data scientist
The data organized by ETL is still not as user-friendly, and further processing by data scientists is needed to enter the modeling phase. For example, if some data is missing, there needs to be some way to fill the gap; The skewness of data is too large, and many statistical methods assume that the data distribution should meet the normal distribution as far as possible, which requires a correction first; It is also necessary to generate derived variables based on business conditions (such as generating weeks, holidays, etc. from dates). Although these tasks are also pre modeling preparations, they require more professional statistical knowledge, and we generally do not consider them as part of the scope of ETL.
There are dozens of modeling algorithms for machine learning, each with its own applicability and a large number of parameters that need to be adjusted. If you use the wrong model or adjust the wrong parameters, you will get very unintelligent results. At this point, data scientists need to constantly try, calculate and examine data characteristics, select reasonable models and parameters, and iterate repeatedly based on the results. It often takes a long time to build a practical model, ranging from two to three weeks or two to three months.
However, in recent years, there have also been some fully automated iterative methods (mainly neural networks), but the calculation time is long and the effectiveness in many fields (such as financial risk control) is not very good. The more effective solution is still led by data scientists, but data scientists are few and expensive….
Do you think the current technology is still a bit low? Behind artificial intelligence, there is no intelligence at all!
Not necessarily, although there are much manual labor that cannot be avoided, efficiency can be improved and some labor can be reduced by selecting certain tools and techniques.
In fact, in order to reduce these “manual labor”, a variety of tools and platforms have emerged in the market, but the quality is uneven, many of which are even more gimmicky. However, there are also some that have been done well. For example, SPL is very useful.
SPL, also known as Structured Process Language, is an open-source, lightweight tool specifically designed for structured data processing, making it convenient for data preparation work. In the meanwhile, it also has the function of automatic modeling, which can reduce some workload of data scientists.
SPL improves the efficiency of data preparation
(1) Syntax design is scientific, without the need to switch between various data types
The content of data preparation work mainly involves various operations and calculations of structured data, and SPL is a language that excels in structured data calculation, with a more scientific and unified design compared to commonly used Python. For example, when using Python, data objects from Python’s native class libraries and multiple third-party class libraries are often used, such as Set (mathematical set), List (repeatable set), Tuple (immutable repeatable set), Dict (key value pair set), Array, Series, DataFrame, etc. Data objects from different libraries are easily confused and difficult to convert, causing a lot of trouble for beginners. Even data objects from the same library can be confused, such as Series and the set DataFrameGroupBy after grouping themselves.
These all indicate that various third-party libraries have not participated in the unified design of Python, nor have they been able to obtain the underlying support of Python, resulting in poor overall language integrity, weak professionalism of basic data types, especially structured data objects (DataFrames), and affecting coding and computational efficiency.
SPL, on the other hand, has a scientifically unified design, with only two types of sets: sequences (similar to List) and table sequences. The former is the foundation of the latter, while the latter is a structured former. The set of a table sequence after grouping is a sequence, and the relationship between the two is clear and distinct. Conversion is easy, and the cost of learning and coding is low.
(2)Rich computational functions
SPL has a variety of computational functions, including traversing loops.(), filtering select, sort, unique value id, group, aggregation max\min\avg\count\median\top\icount\iterate, join, concatenation conj, and pivot.
And SPL has good support for set operations on record sets. For subsets originating from the same set, high-performance set operation functions can be used, including intersection isect, union, and difference diff. For sets with different sources, the merge function can be used with options for set operations, including intersection @i, union @u, and difference @d. In Python, there is no specialized function for calculating the intersection, union, and difference of record sets, which can only be indirectly implemented, making the code quite cumbersome.
In addition to set operations, SPL also has its unique operation functions: groups(group and aggregation), switch(foreign key switching), joinx(ordered association), merge(ordered merging), iterate, enum(enum grouping), align(alignment grouping), pselect\psort\ptop\pmax\pmin(sequence number calculation). These functions are not directly provided in Python and require hard coding implementation.
When performing basic calculations on a single function, there is not much difference between using Python and SPL, but when it comes to work with a certain level of complexity, SPL has an advantage. In actual business, data preparation work usually has a certain degree of complexity.
For example, there is a sales data that we would like to group by year and month, and then calculate the growth rate of each month’s sales compared to the same month last year.
Python implementation:
sales['y']=sales['ORDERDATE'].dt.year
sales['m']=sales['ORDERDATE'].dt.month
sales_g = sales[['y','m','AMOUNT']].groupby(by=['y','m'],as_index=False)
amount_df = sales_g.sum().sort_values(['m','y'])
yoy = np.zeros(amount_df.values.shape[0])
yoy=(amount_df['AMOUNT']-amount_df['AMOUNT'].shift(1))/amount_df['AMOUNT'].shift(1)
yoy[amount_df['m'].shift(1)!=amount_df['m']]=np.nan
amount_df['yoy']=yoy
When grouping and summarizing, Python cannot perform calculations while grouping. Usually, additional calculation columns are added before grouping, which leads to code complexity. When calculating the year-over-year ratio, Python uses the shift function to perform an overall row shift, indirectly achieving the purpose of accessing the “previous record”. In addition, dealing with issues such as zero and null values makes the overall code longer.
SPL code:
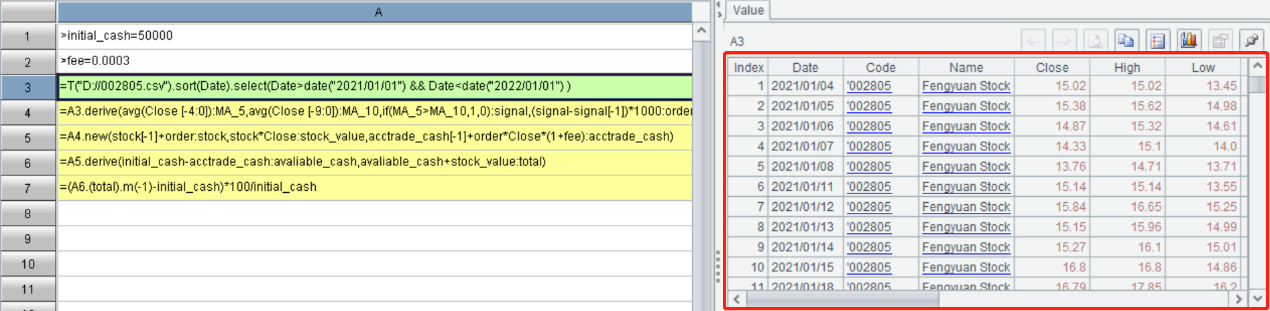
| A | |
|---|---|
| 2 | =sales.groups(year(ORDERDATE):y,month(ORDERDATE):m;sum(AMOUNT):x) |
| 3 | =A2.sort(m) |
| 4 | =A3.derive(if(m==m[-1],x/x[-1] -1,null):yoy) |
When grouping and summarizing, SPL can calculate while grouping, and its flexible syntax brings concise code. When calculating the same period ratio, SPL directly uses [-1] to represent “previous record” and can automatically handle issues such as array bounds and division by zero, resulting in a shorter overall code.
There are many examples of concise calculation of SPL, please refer to the data preparation script: Python Pandas OR esProc SPL? - Comparison between SPL and Python in processing structured data
(3)Excellent big data computing ability
SPL has a perfect cursor mechanism, which can easily process big data. In addition, the usage of most cursor functions is no different from that of in-memory functions, and it is very user friendly. And SPL also has parallel capabilities, supporting multi-purpose usage of one cursor traversal. SPL performs well in aggregation, filtering, sorting, group and aggregation, join, intersection and other calculations commonly used by big data, with simple code and efficient operation. For calculation cases, please refer to the data preparation script: Python Pandas OR esProc SPL? - Comparison between SPL and Python in processing structured data
(4)Intuitive and user-friendly programming environment
In terms of programming style, almost all programming languages are written as text. Each variable has a name, and the results are printed every time you view them. If it’s programming development, there’s no problem, but it’s inconvenient to use for data preparation, i.e. ETL. Although there are interactive tools like Notebook, they are not satisfactory to use. And SPL is much easier to use.
SPL adopts a unique grid style programming, which preserves the calculation results at each step. Clicking on a certain cell can view the calculation results of that step (cell) in real-time, and the correctness of the calculation is clear at a glance. No manual output is required, and the results of each step are viewed in real-time, which is very friendly for ETL work. And it can refer to the calculation result (intermediate variable) within a cell in the form of a cell name (such as A1) like Excel, eliminating the need to brainstorm a bunch of names for various intermediate tables and variables.
(5)Easy to learn
SPL is also very simple to learn. The function syntax is developed according to the natural way of thinking. It is easy to master and draw inferences from one instance. The difficulty of getting started is less than Python and similar to SQL.
SPL implementation for automatic modeling
In addition to being able to efficiently prepare data, SPL also has a library that can implement complete automated modeling. After configuring external modeling library, simple function invocations can be used to achieve automatic modeling. For programmers, there is no need to learn how to preprocess data, nor do they need to learn various complex algorithm principles and parameter applications. As long as they have a conceptual understanding of data mining, they can build high-quality models. For data scientists, there is no need to immerse themselves in repeatedly processing data. In the process of debugging models, SPL greatly reduces manual workload and improves work efficiency.
Taking the classic Titanic survival prediction data as an example, a model can be built with a few simple lines of code:
| A | |
|---|---|
| 1 | =file(“titanic.csv”).import@qtc() |
| 2 | =ym_env() |
| 3 | =ym_model(A2,A1) |
| 4 | =ym_target(A3,“Survived”) |
| 5 | =ym_build_model(A3) |
View model performance:
| A | |
|---|---|
| … | |
| 6 | =ym_present(A5) |
| 7 | =ym_performance(A5) |
| 8 | =ym_importance(A5) |
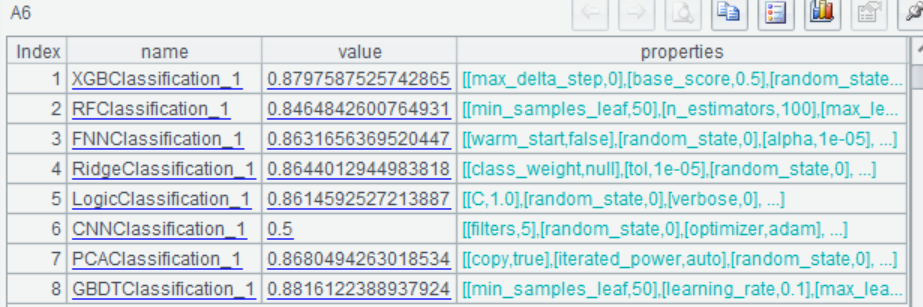
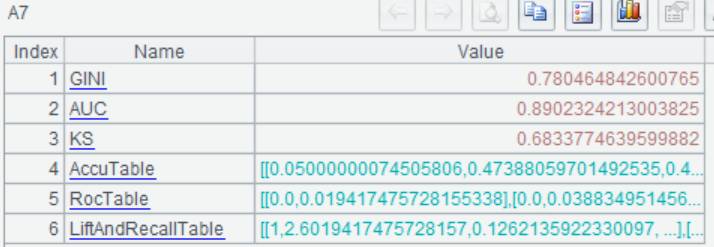
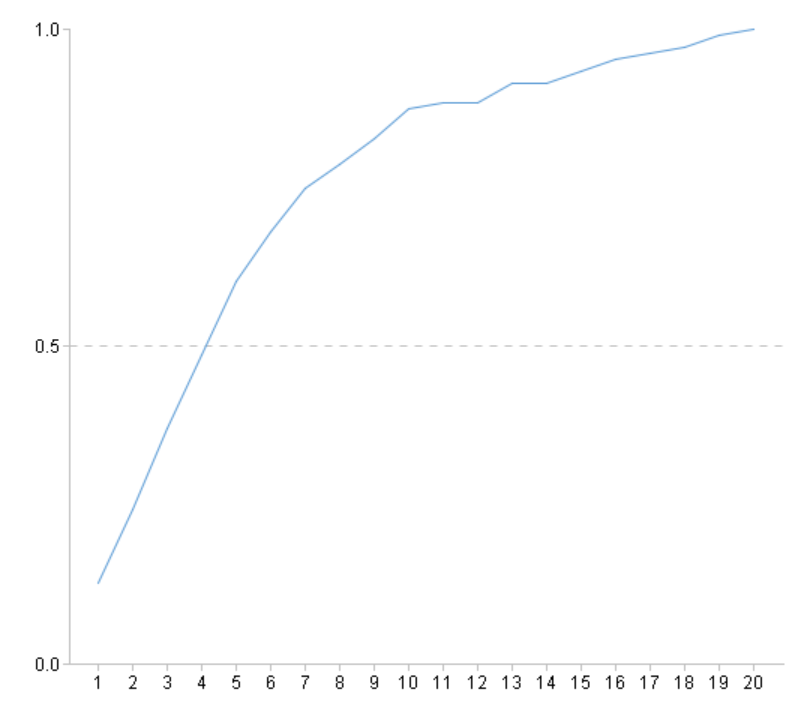
Use the model to predict the probability of survival for each passenger:
| A | |
|---|---|
| … | |
| 9 | =ym_predict(A5,A1) |
| 10 | =ym_result(A9) |
For the complete process, you can refer to: Data mining, modeling and prediction in SPL
The automatic modeling function of SPL can automatically identify the problems existing in the data and preprocess them, such as missing data, exceptions, non-normal distribution, time and date variables, high cardinality variables, etc. After the preprocessing is completed, automatic modeling and parameter tuning will be carried out, followed by model evaluation and output of high-quality models. The entire process is fully automated and does not require manual intervention.
With the help of automatic modeling, it can save data scientists the manual labor of processing data and debugging models, while also lowering the threshold for data mining, allowing non experts to model. Moreover, in practical work scenarios, it is often necessary to build multiple or even many models, and automated modeling methods have more advantages.
For example, banks have a variety of financial products, such as deposits, precious metals, wealth management, installment loan, …… There are also multiple key customer groups, such as the payroll group, the car owner group, …… Banks need to explore potential customer lists, recommend financial product portfolio packages, and conduct synchronous marketing of multiple product portfolios for target customers. In this case, there are multiple products and customer groups, and in order to achieve the goal, it is necessary to build many models (dozens or even hundreds). If all of them are built manually, it will require a lot of manpower and time, and can almost be said to be a huge task. While using automatic modeling technology makes it much easier. Once the data is ready, it can be put into SPL and run quickly. And the effect of the models is also good, with an increase of over 70 times in daily average growth after using the models.
Therefore, although there is still a lot of work to be done by “artificial” behind artificial intelligence, using appropriate tools can also reduce workload and improve work efficiency to a certain extent. SPL can efficiently prepare data and achieve automated modeling, making it an essential tool for machine learning. Moreover, SPL is a very lightweight tool that is easy to install independently or integrate into enterprise systems.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL


Chinese version