

Understand SPL in three aspects
The core data of almost all industries is the structured data, which is the most important data asset of this era. Therefore, how to effectively utilize and process structured data naturally becomes the top priority in business operations. Of course, the structured data processing technologies have been around for a long time, and SQL, Java, Python, and Scala are frequently used among them.
SPL (Structured Process Language, a structured data processing language) is a new structured data processing technology.
Since so many structured data processing techniques are already available, why do we still invent SPL?
This is undoubtedly due to the fact that the existing technologies are often unsatisfactory. The purpose of inventing SPL is to make up for these deficiencies of existing technologies and do further improvement so as to make data processing easier and more efficient.
In this article, we will explore the nature of SPL mainly in three aspects: programming language, computing middleware, and data warehouse.
Interesting programming language
As a professional programming language, why is SPL interesting? What's going on?
What makes SPL interesting is its unique grid-style programming, syntax feature, and more complete computing ability.
Grid-style code
Unlike the text-style code that almost all programming languages adopt, SPL code is written in a grid. The IDE of SPL is as follows:
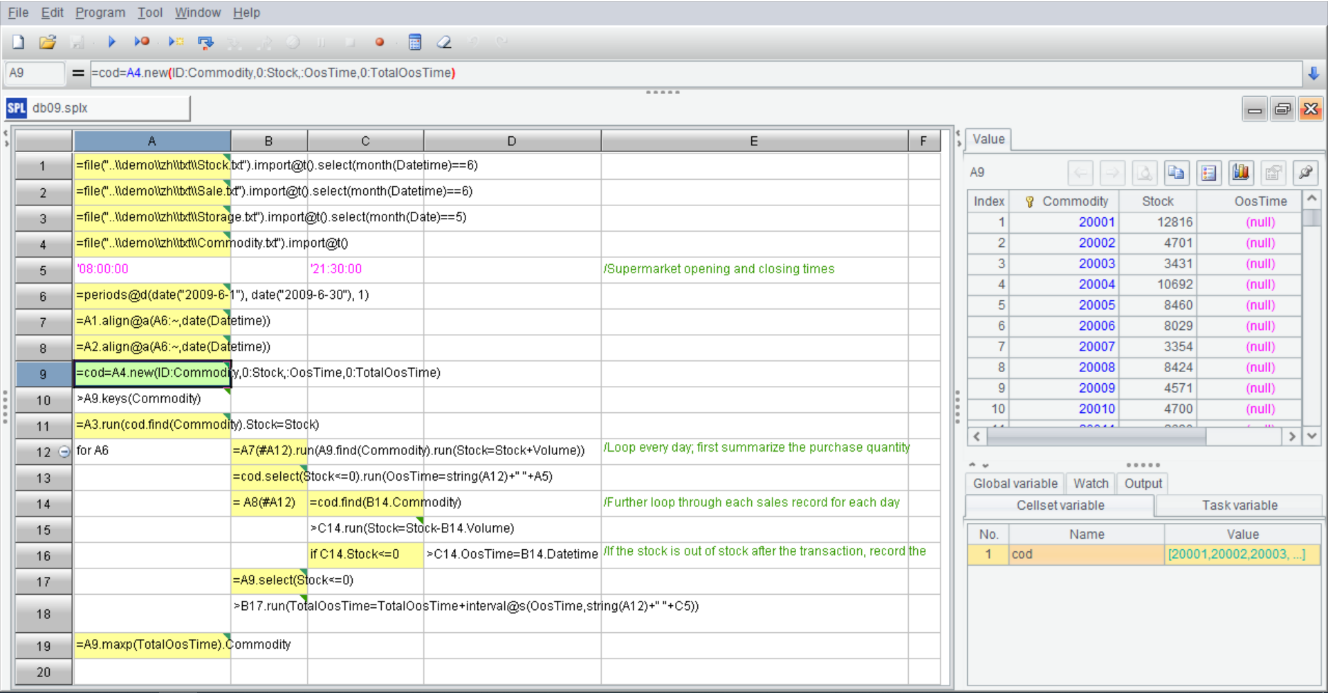
That the grid-style code differs from text-style code is mainly reflected in three aspects. First, there is no need to define variables when coding in SPL. By referencing the name of previous cells (such as A1) directly in subsequent steps, we can get the calculation result. In this way, racking our brains to name variables is avoided. Of course, SPL also supports defining variables; Second, the grid-style code looks very neat. Even if the code in a cell is very long, it will occupy one cell only and will not affect the structure of whole code, thus making code reading more conveniently. Third, the IDE of SPL provides multiple debugging ways, such as run, debug, run to cursor. Moreover, on the right side of the IDE, there is a result panel, which can display the calculation result of each cell in real time. Viewing the result of each step in real time further improves the convenience of debugging.
Syntax feature
As far as the syntax itself is concerned, SPL is also different in many ways, including option syntax, multi-layer parameters, and advanced Lambda syntax.
Each programming language will provide many functions. When some functions have similar functionality, we can distinguish them with the same name but different parameters (types), which is reasonable. However, when it is impossible to distinguish by parameter type sometimes, it needs to explicitly add an option parameter to tell the compiler what we want to do. Yet, the option can also be regarded as a parameter, which will make us confused about the real purpose of these parameters.
In order to solve this problem, SPL provides very unique function option, that is, the symbol @ is used to identify different options. For example, the basic functionality of the select function is to search and filter, if we want to search from back to front, we can use the option @z:
T.select@z(Amount>1000)
If we want to take members starting from the first one until the one that doesn’t meet condition, then we can use the option @c:
T.select@c(Amount>1000)
The two options can also be used in combination:
T.select@zc(Amount>1000)
The parameters of some functions are very complex and may be divided into multiple layers. In view of this situation, conventional programming languages do not have a special syntax solution, and have to generate multi-layer structured data object and then pass them in, which is very troublesome.
To cope with this problem, SPL creatively invents the cascaded parameter, and specifies that three layers of parameters are supported, and they are separated by semicolon, comma, and colon respectively. Semicolon represents the first level, and the parameters separated by semicolon form a group. If there is another layer of parameter in this group, separate them with comma, and if there is third-layer parameter in this group, separate them with colon.
For example, it is very easy for SPL to perform a join operation:
join(Orders:o,SellerId ; Employees:e,EId)
Today many programming languages either do not support Lambda syntax or support only in a limited way. Let's still take Java to illustrate: for simple calculations, it is indeed convenient to code in Lambda expression, but for slightly complex calculations, it is not easy, e.g., the grouping and aggregating operation on two fields not only needs to define the data structure in advance, but it will also form nesting of two anonymous functions, resulting in a difficulty to write and understand the code.
SPL also supports Lambda syntax, and the support degree is more thoroughly than other languages like Java. When we perform the above grouping and aggregating operation in SPL, there is no need to define the structure in advance, nor does it have to nest multiple layers, and the SPL code is simple and easy to understand:
Orders.groups(year(OrderDate),Client; sum(Amount),count(1))
In addition, SPL adds some symbol like ~, # and [] to represent the current member, sequence number and relative position respectively. For example, if we want to reference the previous record, we can write [-1]. With these symbols, any calculation can be implemented without adding other parameter definition, and the description ability becomes stronger, and writing and understanding are easier.
Computing ability
Compared with the languages (like Java) that lack necessary structured data object, SPL provides a specialized structured data object: table sequence and provides rich computing library based on the table sequence. In addition, SPL supports dynamic data structure, which makes SPL have complete structured data processing ability.
Here below are part of conventional calculations in SPL:
Orders.sort(Amount) // sort
Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) // filter
Orders.groups(Client; sum(Amount)) // group
Orders.id(Client) // distinct
join(Orders:o,SellerId ; Employees:e,EId) // join
Complete structured data processing ability makes SPL comparable to SQL, and makes it look like SQL that does not depend on database. In fact, the ability of SPL goes beyond that. Since SPL has a deeper understanding of structured data, it is stronger in many respects.
For example, SPL supports ordered operation more directly and thoroughly. Let’s see a case: calculate the maximum number of trading days that a stock keeps rising based on a stock transaction record table. For this calculation task, it is easy to implement in SPL:
stock.sort(trade_date).group@i(close_price<close_price [-1]).max(~.len())
In contrast, when this calculation task is implemented in SQL, it needs to nest 3 layers, and even with the help of window function, it still needs to code in a roundabout way due to the fact that SQL lacks support on ordered operation.
For the grouping operation, SPL can retain the grouped subset, i.e., the set of sets, which makes it convenient to perform further operations on the grouped result. In contrast, SQL does not have explicit set data type, and cannot return the data types such as set of sets. Since SQL cannot implement independent grouping, grouping and aggregating have to be bound as a whole.
In addition, SPL has a new understanding on aggregation operation. In addition to common single value like SUM, COUNT, MAX and MIN, the aggregation result can be a set. For example, SPL regards the common TOPN as an aggregation calculation like SUM and COUNT, which can be performed either on a whole set or a grouped subset.
In fact, many of SPL's features are built on the deep understanding of structured data processing. Specifically, the discreteness allows the records that make up a data table to exist dissociatively, and compute them repeatedly; the universal set supports the set composed of any data, and participating in computation; the join operation distinguishes three different types of joins, allowing us to choose a join operation according to actual situation; the feature of supporting cursor enables SPL to have the ability to process big data... By means of these features, it will be easier and more efficient for us to process data.
For more information, refer to: A programming language coding in a grid
Powerful middleware
The concept of middleware is familiar to us, and SPL can be used as middleware specifically for data computing (DCM: A New Member of Middleware Family).
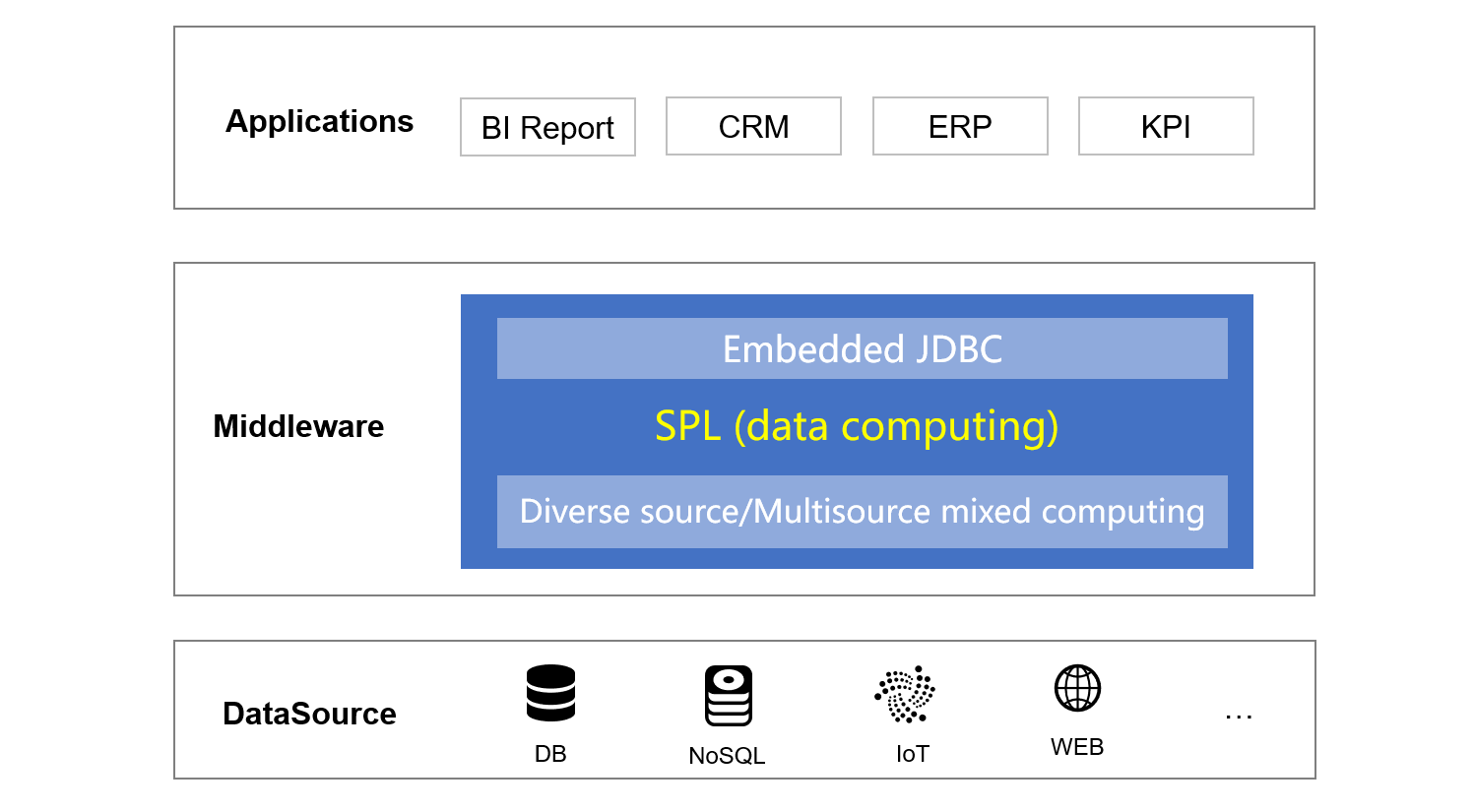
From the perspective of logical structure, SPL can be between data sources and applications to perform multi-data-source mixed computing, and provide data service for applications, which requires SPL to have the following characteristics:
Multi-data-source mixed computing
SPL has open computing ability and can access multiple data sources. For data sources RDB, NoSQL, CSV, Excel, JSON/XML, Hadoop and RESTful, SPL can directly access them and perform mixed computing with no need to load them into database. Therefore, the real-timeness of both the data and the computation can be well ensured.
Integration
Logically, SPL is between the data source and the application, but physically, SPL can be integrated with applications. SPL supports integrating by embedding jar. After integrating, SPL can be deployed together with application, which is very flexible and lightweight.
Agility
From the introduction of the programming languages in the previous section, we know that SPL has good agility. For the same calculation task, it is easier to implement in SPL, which makes SPL, as a computing middleware, have the ability to quickly respond to diverse data computing requirements.
Hot swap
SPL, as an interpreted-execution programming language, naturally supports hot swap and hot deployment. This feature is very friendly to some businesses (such as report and microservice) that are less stable and often need to add or modify computing logic.
High performance
SPL has built in many high-performance algorithms, e.g., after SPL regards the TopN operation mentioned above as an aggregation operation, big sorting is avoided, thereby achieving higher performance. In addition, SPL provides many mechanisms like index, ordered computing and parallel computing, which can further ensure performance.
Through the above characteristics, we can see that among the existing technologies, the database (SQL) is too heavy and closed to serve as a computing middleware. In addition, database cannot perform cross-source computing, especially the computing across different type of data sources; although Java can be used as a computing middleware from the perspective of framework, Java is unsuitable for serving as middleware due to the lack of support for structured data computing.
Then, what are the application scenarios of SPL as middleware?
Agile computing
Since the data processing logic in application can be implemented only through coding, it is difficult for native Java to implement due to the lack of necessary structured data computing library. Even if the newly added Stream/Kotlin is utilized, it still fails to make significant improvement. While the development dilemma can be alleviated to a certain extent with the help of ORM technology, it still lacks professional structured data type, resulting in less convenient for set operation. Moreover, it is cumbersome to code when reading/writing database, and it is difficult to implement complex calculations. These shortcomings of ORM often lead to a failure to significantly improve the development efficiency of business logic, or even result in a significant decrease. Additionally, these implementation ways will also cause problems with application framework. The computing logic implemented in Java must be deployed together with main application, resulting in tight coupling, and the development, operation and maintenance are very troublesome since Java doesn’t support hot deployment.
With the help of SPL's features like agile computing, easy integration and hot swap, replacing Java with SPL in applications to implement data processing logic can effectively solve the above problems. In this way, the development efficiency is improved, and the application framework is optimized, and thus achieving the decoupling of computing module. Moreover, SPL supports hot deployment.
For more information, visit: SPL: The Open-source Java Library to Process Structured Data
Computation of diverse data sources
Diverse data sources are characteristic of modern applications. If these data sources are processed in database, not only does it require loading data into database, which is inefficient, but it also cannot ensure data real-timeness. In addition, different data sources have their own advantage. Specifically, RDB is strong in computing ability, but weak in I/O throughput; NoSQL has high I/O efficiency but is weak in computing ability; files like text data are very flexible to use but do not have any computing ability. Loading such data into database will lose their own advantage.
By means of SPL’s mixed computing ability on diverse data sources, we can perform mixed computing directly on data from RDB, text file, Excel, JSON, XML, NoSQL or data from network. Therefore, the real-timeness of both the data and the computation is ensured, and the advantage of every data source is leveraged.
For more information, visit: Which Tool Is Ideal for Diverse Source Mixed Computations
Microservice implementation
Currently, the implementation of microservice still depends heavily on Java and database for data processing. However, it is complex to implement in Java, and Java does not support hot swap; as for databases, due to the limit of “base”, the calculation can be performed only when multiple data sources are loaded into database, this is inflexible, and cannot ensure the real time of data, and cannot give full play to each source’s advantages as well.
By embedding the integrable SPL in each stage of microservice implementation to perform data collection & organization, data processing and front-end data computing, and utilizing SPL’s open computing system, each data source’s advantage can be brought into full play, and the flexibility is enhanced. The problems such as multi-source data processing, real-time computing, and hot deployment can all be easily solved.
For more information, visit: Open-source SPL Makes Microservices More "Micro"
Replacement of stored procedure
Stored procedure was often used to implement complex calculations or organize data. Stored procedure has certain advantages in in-database computation, but its disadvantages are also obvious, specifically reflected in: it is hard to migrate, edit and debug stored procedure; creating and using stored procedure require high database privilege that poses data security threats; stored procedure serving the front-end application will cause tight coupling between the database and the application.
With SPL, we can place the stored procedure in the application to create a stored procedure outside the database, and the database is mainly used for storage. Separating stored procedure from the database eliminates various stored procedure related problems.
For more information, visit: Goodbye, Stored Procedures - the Love/Hate Thing
Data preparation for reporting & BI
Preparing data source for report development is an important task of SPL as a computing middleware. The conventional practice of doing the job in the database has a series of problems like complicated procedure and tight coupling. Reporting tools themselves cannot handle complex computations due to weak computing abilities. SPL offers database-independent, powerful computing ability to create a special data computing layer for report development, which decouples computations from the database and reduces the database’s workload and makes up for the shortage of reporting tool’s computing ability. Besides, the logically separate computing layer helps to make development and maintenance light and convenient.
After instrumentalizing the data preparation of report development under the help of SPL, together with the reporting tools, we can adapt quickly to the changing reporting requirements, and handle endless report development tasks at lower cost.
For more information, visit: The Open-source SPL Optimizes Report Application and Handles Endless Report Development Needs
T+0 queries
When data accumulates to a relatively large size, querying on production database could affect transactions. To address this issue, the large amount of historical data will be split away and stored in a separate, special database. This is the separation of cold data from hot data. Now querying the whole data get cross-database computations and routing between hot data and cold data involved. Databases have troubles dealing with cross-database queries, particularly those between different database products, which leads to inefficiency. There are other problems like instable data transmission and low extensibility that prevent convenient and efficient T+0 queries.
SPL can solve all those problems. With independent and all-around computing ability, it can retrieve data from different databases respectively and thus handle scenarios involving different types of data sources well. With SPL, we can select the best place where the computation will be handled, the SPL or the database, according to the database’s resource load. This is flexible. In the aspect of logic implementation, SPL’ agile computing ability can streamline complex computing procedures for T+0 queries and increase development efficiency.
For more information, refer to: Create Easy and Efficient T+0 Queries with Open-source SPL
Efficient data warehouse
Not only does SPL have independent and all-around computing ability, but it also has specialized storage. With these two characteristics, SPL can be used as a data warehouse.
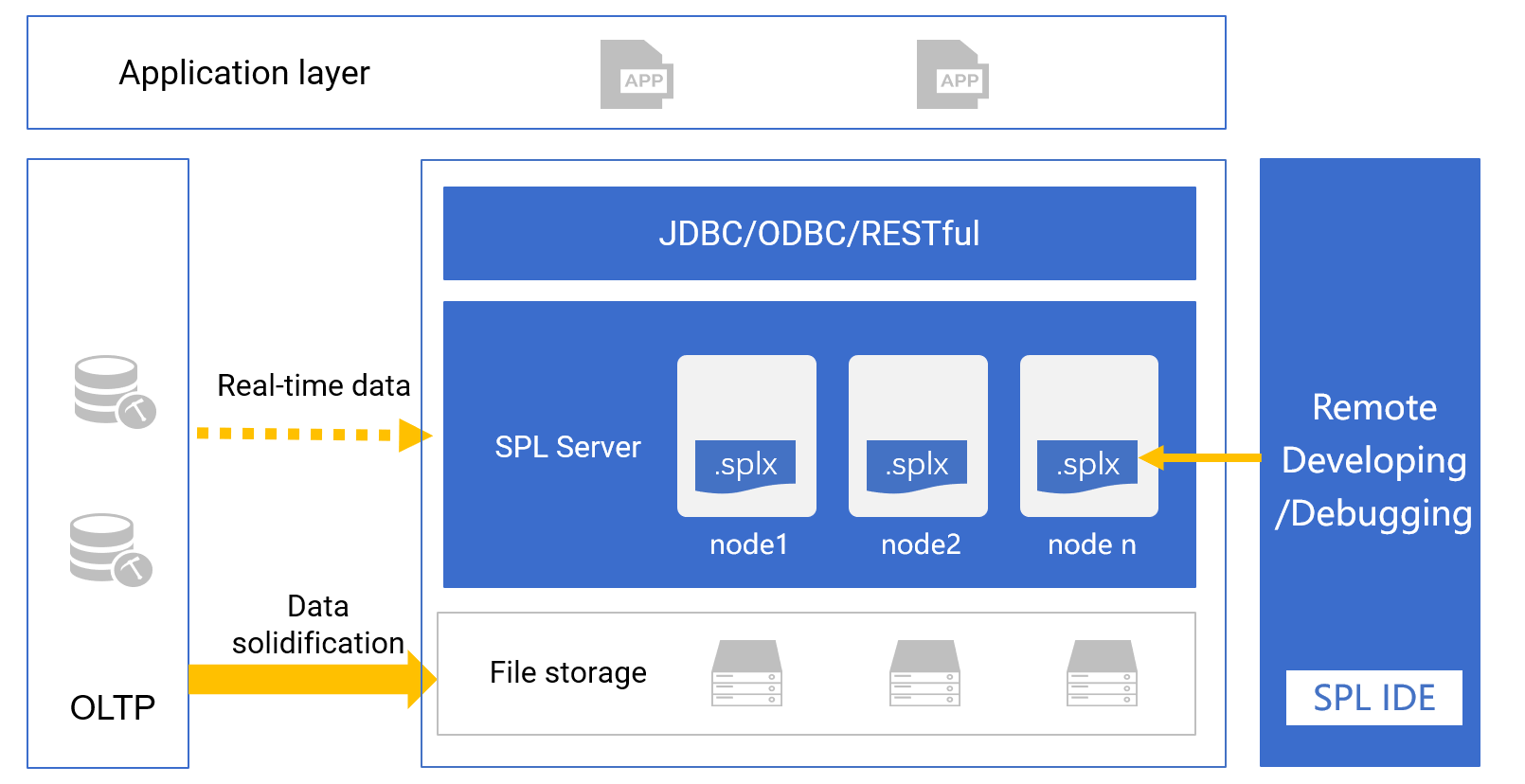
As can be seen that SPL as a data warehouse is structurally almost the same as traditional data warehouse, and both of them run on an independent server (which can be scaled out). The business data needs to be solidified into data warehouse through ETL, and application accesses SPL service through a unified JDBC/Restful interface.
Nevertheless, SPL is very different from traditional data warehouse in certain aspects.
SPL data warehouse uses SPL language rather than SQL
The formal language of SPL data warehouse is SPL, not SQL commonly used in the industry. As for the reason, we roughly mentioned it in the previous programming language section. In this section, we will explain in detail. Simply put, SQL, which was born decades ago, cannot well suit to the needs of contemporary business, and will face the situations of being difficult in coding, slow in running or even unable to code. By contrast, SPL can solve these problems. Now we will compare them in the following aspects.
Development efficiency
For slightly more complex calculations, it is very difficult to code in SQL. For example, if the above stock case is calculated in SQL, the code is:
select max(continuousDays) – 1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case
when closePrice > lag(closePrice)
over(order by tradeDate) then
0
Else
1
end changeSign
from stock))
group by unRiseDays)
The detail of this code will not be explained here. Overall, it is coded in a very roundabout way.
Coding in SPL:
A |
|
1 |
=stock.sort(tradeDate) |
2 |
=0 |
3 |
=A1.max(A2=if(closePrice>closePrice[-1],A2+1,0)) |
With the support of ordered operation and procedural computing, this code can be expressed completely following natural thinking, and is simple and easy to understand.
Here below is another coding way (this code is already given earlier):
stock.sort(trade_date).group@i(close_price<close_price [-1]).max(~.len())
This code is written according to the logic of above SQL code, and is also very simple and easy to understand because of the support of ordered operation.
Another case: calculate the moving average of sales of the month before and after each month based on sales records:
SQL code:
WITH B AS
(SELECT LAG(Amount) OVER(ORDER BY Month) f1,
LEAD(Amount) OVER(ORDER BY Month) f2,
A.*
FROM Orders A)
SELECT Month,
Amount,
(NVL(f1, 0) + NVL(f2, 0) + Amount) /
(DECODE(f1, NULLl, 0, 1) + DECODE(f2, NULL, 0, 1) + 1) MA
FROM B
This calculation can be implemented with just one SPL statement:
Orders.sort(Month).derive(Amount[-1,1].avg()):MA)
Simple in coding means higher development efficiency, simpler operation and maintenance, and lower operation cost, all of which stem from SPL's deep understanding on structured data computing.
Computing performance
Difficult in coding usually leads to poor performance. Conversely, simple in coding usually obtains high performance. We know that any data warehouse offers optimization engine, and a good engine has the ability to guess the real intention of a query statement, and then adopt a more efficient algorithm to execute the statement (instead of executing according to the literally expressed logic). For example, calculate TOPN:
SELECT TOP 10 x FROM T ORDER BY x DESC
Although this SQL statement contains sorting-related words (ORDER BY), most data warehouses will optimize and will not sort.
However, if we calculate the in-group TOPN:
select * from
(select y,*,row_number() over (partition by y order by x desc) rn from T)
where rn<=10
While the complexity of this SQL statement does not increase much, the optimization engine of many databases will get confused and can't guess its real intention. As a result, a big sorting has to be carried out according to literally expressed meaning. As big data sorting is a very slow action, it ultimately leads to poor performance.
Actually, this calculation can be implemented with an algorithm that doesn’t require big sorting. However, SQL cannot express such algorithm, and has to turn to the optimization engine. Unfortunately, the optimization engine will get confused once the calculation becomes complex, resulting in a failure to utilize an execution way with higher performance. This is the dilemma that traditional data warehouse (SQL technology) is facing.
SPL provides many high-performance algorithms in order to solve complex calculations. For example, SPL regards the in-group TOPN as an aggregation operation (returning a set instead of a single value), the sorting of all data is thus avoided in practice, thereby achieving higher performance.
SPL provides dozens of high-performance algorithms to ensure computing performance, including:
· In-memory computing: binary search, sequence number positioning, position index, hash index, multi-layer sequence number positioning...
· External storage search: binary search, hash index, sorting index, index-with-values, full-text retrieval...
· Traversal computing: delayed cursor, multipurpose traversal, parallel multi-cursor, ordered grouping and aggregating, sequence number grouping...
· Foreign key association: foreign key addressization, foreign key sequence-numberization, index reuse, aligned sequence, one-side partitioning...
· Merge and join: ordered merging, merge by segment, association positioning, attached table...
· Multidimensional analysis: partial pre-aggregation, time period pre-aggregation, redundant sorting, boolean dimension sequence, tag bit dimension...
· Cluster computing: cluster multi-zone composite table, duplicate dimension table, segmented dimension table, redundancy-pattern fault tolerance and spare-wheel-pattern fault tolerance, load balancing...

Some of these algorithms are pioneered in the industry. In addition, SPL provides corresponding guarantee mechanism for different computing scenarios. Compared with traditional data warehouse, SPL is richer in both algorithm and guarantee mechanism, which can fully ensure computing performance.
In practice, when serving as a data warehouse, SPL does show different performance compared with traditional solutions. For example, in an e-commerce funnel analysis scenario, SPL is nearly 20 times faster than Snowflake even if running on a server with lower configuration; in a computing scenario of NAOC on clustering celestial bodies, SPL is 2000 times faster than the distributed database of a certain leading Internet company even if running on a single server. There are many similar scenarios where SPL is basically able to speed up several times to dozens or even thousands of times, showing very outstanding performance.
However, SPL did little in automatic optimization compared with traditional warehouse, and depends almost entirely on programmers to write low-complexity code (i.e., the combination of the built-in functions) to achieve high performance. In this case, programmers need receive some training to familiarize themselves with SPL’s philosophy and library functions before getting started with SPL. Although this is an extra step in comparison with SQL, it is usually worthwhile as it enables us to improve the performance by order of magnitude, and reduce the cost by several times.
Technology stack
As a complete computing language, any calculation can be coded in SQL theoretically. However, if the computing scenario is too complex, and difficult to implement in practice, then we think SQL doesn’t have the ability to handle. In fact, such scenario is common.
For example, for the e-commerce funnel analysis scenario for calculating user churn rate, it is difficult to code in SQL. As a result, most of us will naturally think SQL is not suitable for such multi-step calculation involving order.
In fact, the industry has already realized the limitations of SQL in dealing with complex calculations, and started to introduce Python, Scala, and some technologies like MapReduce to some data warehouses to solve such problems. Unfortunately, the effect is not satisfactory so far. This is due to the fact that MapReduce is too poor in performance, extremely high in hardware resource consumption, very cumbersome in coding, and still difficult to implement many calculations; although Python's Pandas is relatively powerful in logical function, it doesn't do a good job in terms of details. Obviously, Pandas is not elaborately designed, as there are many duplicate content and style inconsistency, and it’s still not easy to describe complex logic. In addition, it is difficult to obtain high performance due to the lack of big data computing ability and corresponding storage mechanism; As for Scala, it is inconvenient to utilize its DataFrame object. In addition, Scala doesn’t provide sufficient support for ordered operation, and the large number of record copying actions generated during computation will lead to poorer performance, to some extent, it even is a regression. Moreover, these technologies with completely different styles will increase the complexity of technology stack. Heavy and bloated framework as well as complex technology stack of SQL dramatically increases the O&M cost.
In contrast, the computing ability of SPL is more open. SPL offers more comprehensive functionality, making it easy to implement complex calculations, and hence most calculation tasks can be achieved without resorting to other technologies, the technology stack is more unified, and the O&M cost is lower.
File storage
In terms of data storage, there is a big difference between SPL and traditional data warehouse.
Logically, traditional data warehouse organizes data as a whole. Data on the same theme forms a database, and there is a set of metadata to describe the structure and relationship of data in the database. A clear boundary exists between data inside and outside the database, which is what we often refer to as closedness. Due to the closedness, not only does the data need to be stored in database, but it often needs to bypass the operation system to directly access hard disk during computing, which will result in deep binding of storage and computation and is disadvantageous for implementing the separation between storage and computation. This mechanism is an obstacle to utilizing cloud. To use network file system and cloud object storage, reconstructing from the base-level is required, yet this will cause many risks.
In contrast, SPL has no metadata. The data is directly stored in files, and any type of open file can be processed. In order to ensure computing performance, SPL also designs a specialized binary file format. Since the binding of storage and computation caused by closedness is eliminated, it allows users to separate storage from computation easily, and then implement elastic computing. Therefore, the utilization of cloud becomes easier.
In addition, the cost of file storage is lower. In AP computing scenario, users can flexibly design a space-time trade-off scheme, which is nothing but storing a few more files. Even if the number of redundant files reaches over ten thousand (it is easy for contemporary file systems to handle data of such a scale), there isn’t any burden. Also, it is simple to manage data files by category under the file system’s tree structure. And the cost of operations and maintenance is lower.
For more information, visit: Data warehouse running on file system
Openness
We know that traditional data warehouse is developed based on database, so it inherits database’s many features, such as metadata and data constraints. Consequently, computation can be performed only after the data is loaded into “house”, which is equivalent to setting up a “city wall”, and that the data is inside or outside the wall is strictly defined. Overall, traditional data house exhibits the same nature as database, i.e., the closedness.
Today, however, data fed to applications come from a much wider range of sources. There are a variety of data sources and so are their formats. The closed databases cannot open their computing ability to data outside it, but can only load the data into it for further computation. This adds an ETL action, increases workload for both the programmer and the database, and results in the loss of data real-timeness. Often data outside the database has irregular formats, and it is not easy to load it into databases having strong constraints. Moreover, even ETL requires to first load the raw data into the database in order to use the latter’s computing ability, resulting in ELT and increased database workload.
SPL has stronger openness. Any accessible data can be computed. The only difference is that data sources have different access performance. In SPL, there are specialized high-performance file storage formats. Logically, there isn’t any difference between data stored in these formats and data retrieved from a text file or from RESTful. Even data coming from a SQL database can be handled in the same way. These are manifestations of open computing ability. Since open computing ability eliminates the limit of “city wall”, higher computing efficiency is obtained, and the building of Lakehouse is more convenient.
For more information, visit: The current Lakehouse is like a false proposition
Furthermore, the openness of SPL is also reflected in the utilization of real-time data. The ETL process accompanying the loading of business data into database will result in a decrease in data real-timeness. Since SPL supports mixed computing of different type of data sources, it is more convenient to implement T+0 queries. Specifically, querying cold data based on the data warehouse, and querying hot data based on the production database (the amount of hot data is small, and querying it will not cause too much burden), and depending on SPL’s cold and hot data mixed computing ability, T+0 queries can be implemented. With this ability, users can build HTAP without changing the existing production database.
For more information, visit: HTAP database cannot handle HTAP requirements
Summary
SPL can be used not only as a programming language, computing middleware, but also as a data warehouse, reflecting its versatility, which stems from the diversity of its structured data application scenarios, and the openness, agility, and high performance of its technology. For traditional data processing technologies, there is almost no more breakthrough in theory, so what are competed is the engineering optimization ability. Yet, it is difficult to make up with certain theoretical shortcomings through engineering method, and therefore both the theoretical foundation and engineering practice are necessary. Fortunately, the “emerging” SPL has both of these conditions, and is definitely worth a try.
SPL Official Website 👉 https://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProcSPL
SPL Learning Material 👉 https://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/2bkGwqTj
Youtube 👉 https://www.youtube.com/@esProc_SPL

