

Thirteen Things Which Beginners Should Know about Data Mining
Introduction
It’s a trend to commercialize data mining technologies in this big data era. But, for novice data miners the concept of data mining needs to be clarified because they don’t know how to mine the data even if they have “a gold mine” and because they have a very superficial impression of data science.
For the puzzled starters, we collect a set of frequently asked questions and give detailed illustrations, ranging from the basic concept, project process to almost all aspects of the technological application.
We also have a data mining crash course for those who wants to engage in data mining but starts from zero.
Content
2. What type of data model building needs?
3. How long does it take to complete a data mining project?
4. What are the obstacles of expanding the use of data mining in business analytics?
5. What are the differences between veterans and novices?
6. Why can’t I build the same effective model with open-source tools?
7. Why is Python the most popular languagte for data mining?
8. Is an AI crash course necessary?
9. What is deep Learning? What can it do?
10. Why business knowledge is crucial for building effective models?
11. What are the benefits of batch modeling?
12. What is the attenuation of models?
13. Is the higher the model precision the better?
1. What does data mining do?
Data mining is not something new. It is decades of years old. The concept, however, has stepped in the spotlight in recent years thanks to the popularity of AI.
What is data mining? And what is it used for?
Imagine you are taking a walk in an evening after a light drizzle. The road is moist, the breeze is gentle and there are a few sunset clouds on the sky. “Tomorrow will be another fine day”. You think to yourself. There is a roadside stand where watermelons are sold. You walk up to it and pick a dark green one. It has curled stem at the bottom and muffled sounds when thumped. “Such a perfect melon”! You say to yourself.
You made predictions about the weather and the watermelon’s degree of ripeness based on your experience. The moist road, gentle breeze and sunset clouds indicate fine weather the next day. And the curled stem at the end, muffled tapping sound, and the dark green color suggest a great-tasting melon.
Humans can see the future based on their experience. Can a computer perform predictions for us?
Yes. That’s what data mining is all about.
When the “experiences” take the form of “data”, data mining is used to dig from them – the historical data – such as those of selecting watermelons, the useful “knowledges” to gain experience, that is, the model. Then when one is buying a watermelon again, they can use the model to predict whether it is good or not.
Fundamentally, the aim of data modeling is to work out a function (f) or a model, according to the existing mapping between the input space X (like {[dark green; curled stem; muffled sound], [black; curled stem; thud sound], [pale; stiff stem; ping sound]}) and the output space Y (like {ripe; overripe; unripe}), in mathematical language that a high school student can understand. With the model, it’s easy to make predictions by calculating the function over a new input space (x) to get an output space (y).
Watermelon dataset
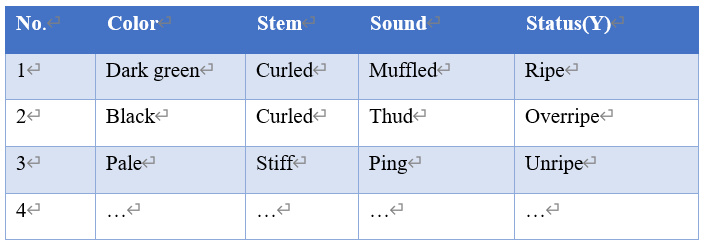
How is a model created? Or how do we get the function?
What will you do if you want to learn the skills of choosing a great-tasting watermelon?
First we observe a sufficient number of watermelons to get a good knowledge of their characteristics (colors, shape of stem at the bottom, tapping sound, etc.). Then we cut each open to see their status. The more we observe and do the verifications, the stronger the ability of choosing a perfect melon according to the above features. To put it simply, the more the watermelons we observe, the more the experience we will get and the higher the skill to make accurate judgements.
The same goes for doing computer-based data mining. We use the historical data (the sufficient number of watermelons) to create a model. The modeling process is called training or learning; and the historical data is known as training dataset. A trained model represents a regular pattern of the historical data and can be used to predict things.
So data mining is used for prediction based on enough historical data that has conclusions.
How can we apply the technique in the real-world businesses?
Take loan business as an example. A financial institution uses risk management to reduce the probability of bad loans. The risk management includes assessing a borrower’s ability to make payments on time in order to decide whether or not to lend them money and the interest rate.
A certain amount of historical data about the loan businesses and the borrowers is needed to do the risk management. Factors that influence the default rate include the borrower’s income level, educational level, the neighborhood where they live, credit report, debt ratio, as well as the amount, tenure and interest of the loan. The historical data must include both high-quality clients and clients with bad credit (they have the history of failing to pay bills on time). And the number of the latter should not too small.
Generally we use the historical data during recent months or the past year as the training data, define the target variable Y (1 for clients with bad credit and 0 for high-quality clients), and build a model using the data mining technique that displays the relationship between the existing information (X) and the target (Y). We can then use the model to identify the high-risk borrowers among the clients.
We should know that no mining model is 100% accurate though we have matrices to assess their accuracy. It makes no sense to predict one target, a single sum of money lent for instance. Normally we have a lot of targets to be predicted. Though not all targets are precisely predicted, the accuracy is on a certain range. That’s useful for a real-world business. For a loan business, for instance, the high-risk borrowers predicted by the model do not necessarily fail to make payments on time. But as long as the accuracy is maintained in a relatively high level, we are able to reduce the risk effectively.
Data mining technologies have been widely applied in various fields. There are lots of examples – people use them to predict the percentage of qualified products in the manufacturing industry based on the historical data and then find solutions to reduce the ratio of disqualified products; to forecast a disease outbreak among the livestock according to their body temperature and then take preventive measures; to build a link between symptoms and diseases on the basis of the historical patient record in order to help doctors identify diseases faster and more precisely – you name it.
2. What type of data model building needs?
Rather than the eye-catching unstructured data, model building is based on structured data. Data modeling and scoring is always the computation over structured data.
Structured data means data is stored in a two-dimensional format in a row-wise way (a row is also known as a sample). Each row represents an entity’s information under same attributes (also known as fields or columns). The structured data originate either from a database or a text file or Excel file.
The table below stores data for predicting the probability of survival among passengers in Titanic. Each row of the structured data represents a passenger sample. Each column accommodates one attribute (Age column, for instance, contains ages of the passengers). This is the right table for model building.

Supervised learning requires that the training data contain the target variable, which is our prediction object. In the Titanic example, the prediction object is the passenger status (survived or dead) represented by Survived field. This is the target variable the model needs to predict. A certain number of related characteristic variables are also needed. You cannot build a good model if there are too few characteristics variables or all the other characteristics are unrelated.
There also should be sufficient quantity of training data. You cannot train an algorithm to learn the data pattern if there are too few training data. Even a simple model building task needs hundreds of or thousands of samples. Sometimes the quantity of samples is enough but there are few positives – which are the concerned data (imagine there are few malfunction records in the historical data when one wants to make prediction on failures). In this case it’s not possible to build an effective model. But on the other hand, it’s not a good sample if all is positive. To build a model to predict the default probability, for instance, information of both clients with bad credit and the general clients should be collected.
Yet bigger is not always better for an ideal training data set. A traditional data mining technique doesn’t need a huge training data set. Generally a quantity of tens of thousands of or over one hundred thousands of samples are sufficient. A bigger training data set requires longer computing time and more resources but it has little effect on building a better model and even could contain more noisy data. So, an appropriate and balanced number of samples and characteristics is the key of model building.
3. How long does it take to complete a data mining project?
Generally a standard model development process has six phases: (1) Business understanding; (2) Data understanding; (3) Data preparation; (4) Modeling; (5) Evaluation; and (6) Deployment. The workflow is convenient and practical.
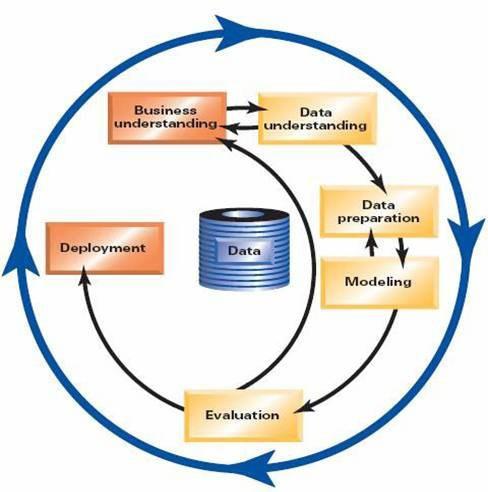
The business understanding phase includes finding out what you or the customer really wants to accomplish, understanding the business situation that drives the project, defining business goals and business success criteria. The data understanding phase is often carried out together with the first phase. It includes six tasks – gathering data, describing data, exploring data, verifying data quality, defining data mining goals and modeling success criteria. The most important tasks in the first two phases are defining data mining goals and gathering data. Then you can set about preparing the data.
The object of data preparation phase is to create a data mart or a wide table. Its tasks include selecting data, cleaning data, constructing data, integrating data and formatting data. This would be a simple phase that covers only data selection and integration if the enterprise data warehouse is sophisticated enough. If the data used for data mining is raw data, such as log data and flow data, you will need a lot of time and effort to do the data integration and feature extraction jobs.
The modeling phase is the most important and most challenging part of the data mining project. You need to choose a right preprocessing technique according to parameter settings, data types and class distributions. The tasks include selecting modeling techniques, adjusting parameters and modeling assumptions. These involve a series of jobs – selecting samples, defining training samples, test samples & verification samples, data preprocessing, choosing modeling algorithm, variable selection, model training and model assessment. There are two points: one is that the data preprocessing is time-consuming; the other is that you need to optimize the modeling algorithm iteratively to get the best model.
The evaluation phase assesses the model performance according to a series of metrics, including AUC, Gini, KS, Lift and model stability, and tests the model in a practical application to determine whether it can meet the business goals. In the final deployment phase, we deploy the model to put it to work in our business.
The duration of the modeling process is influenced by the sophistication level of an enterprise’s data warehouse, the complexity degree of the business problem and model building and the modeler’s skills. Yet, even there is already a sufficiently sophisticated data warehouse platform, so we don’t need to concern about data preparation and can focus on the model building only, generally a simple data mining task will still take two to three weeks. It’s also not a rare thing to take several months to complete a more complicated task.
Why does the model building take so long?
The data preprocessing pays off but it is time-consuming. How to handle missing values and high cardinality categorical variables, or the noisy data, or various other situations? All these require a lot of expert knowledge and experience to tune the algorithm iteratively. For example, in the raw data, 5% customers haven’t age values, and how should you handle them? There are several choices. The first is to ignore the age variable. The second is to ignore the samples that containing the missing values. The third is to fill the empty fields with mean or median of the column or using a more complicated method. The last is to train two models where one contains this characteristic and the other doesn’t contain the characteristic. But when the missing rate reaches 90%, maybe we should consider if the current method is suitable.
The model building process is time-consuming, too. We need to iteratively explore which and how many algorithms we should use, how to configure the initial parameters and how to find the optimal solution, and etc. This is an iteratively optimized process until the best possible result is achieved rather than a target accomplished at one stroke. And it’s often the case that we should go back to square one and start all over again.
So the data mining process is both mentally- and physically-challenging. It’s almost impossible to achieve batch modeling in this case. Generally one data mining project is only able to build one model. This model is thus expected to be as widely-applied as possible. Yet such a model will be not so adaptable. Forecasting house prices would be more accurate and effective if we built models based on different regions instead of building a universal one for the whole country. Precision marketing models would help lead to a more accurate result if they were built for different products and customers with various buying habits.
Yet there is good news. The development of AI technologies makes it possible to use smart tools to simplify and speed up the data mining process. An automatic modeling technique is intended to automatically explore and preprocess data, choose the best model, adjust parameters and evaluate the model performance. An automatic modeling tool will do as much the iterative exploration work as possible and leave data analysts to handle just the business understanding phase and the data preparation phase. So the model building process can be reduced from several weeks to several hours or even several minutes. We don’t need to spend several months to complete a data mining project any more. The tool helps to increase efficiency and reduce workload. As the modeling building process becomes simple and fast, we can use a batch modeling approach to build multiple models in one day. Each model fits for one aspect of a whole or one problem, but all models form a system to be able to be used to predict more complicated targets. An automatic modeling tool lowers the threshold for being a modeler. You don’t need to be a data scientist to become a data miner as long as you know how to use such a tool well.
4. What are the obstacles of expanding the use of data mining in business analytics?
Data mining techniques are hot in all industries. But successful use cases are few. Why?
1. Poor data quality
To mine a lot of “gold” from data in a relatively easy way requires that there be abundant gold in the data. Otherwise you’ll find little gold even if you spend all your effort. The common indicators of poor data quality include:
(1)Lack of data for strategizing
Human babies learning to talk can identify any apples, even if they may have different colors and shapes, after someone tells them that this is an apple several times or only one time. That’s genius.
But so far machines can’t do that. Machine learning algorithms require a large volume of data to get worked. Even a very simple task could need tens of thousands of samples. So the number of samples should not be too few. But that’s not enough. We also need a sufficient number of positives to build an effective model. To predict the malfunction rate, for example, the historical data should contain a certain number of malfunction records.
(2)Atypical data
The training data should be representative samples. To find out if the possess of great wealth makes people feel happier, for example, we download the happiness indexes data from the website of OECD ((https://goo.gl/0Eht9W), pull the per capita GDP data from the website of IMF (http://goo.gl/j1MSKe), combine them and sort the data by per capita GDP to get the following table:
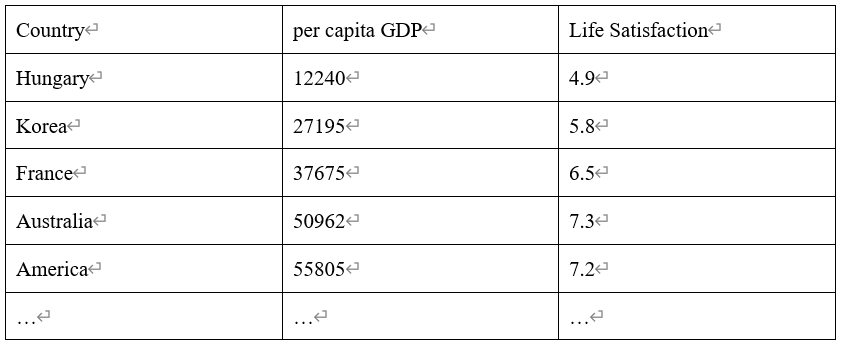
Then we plot a chart of several countries, as the picture below on the left shows:
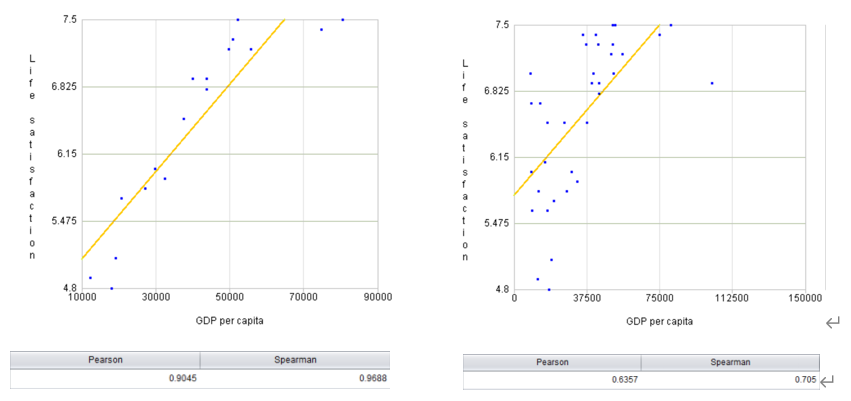
The trend shows an increase of life satisfaction as the per capita GDB rises, though there is noisy data. The linear correlation coefficient between them can be over 0.9. It seems that you can really be happier if you have more money.
The problem is that our training data set is not representative. Data of some countries is missing. By adding the missing data to the training set, we plot another chart (the one on the right).
But the newly-added data results in a quite different model. It shows that linear models may be never accurate enough (because the correlation coefficient is only 0.63 this time). A model built on atypical data won’t make accurate prediction, particularly when most of the samples come from extremely poor countries or the richest countries in the world. That’s why it’s very important to have a typical and representative training data set.
(3)Noisy, abnormal and uncorrected data
The fact is that garbage in, garbage out. It’s hard for an algorithm to find a pattern if the source data is full of errors, abnormal values and noises and, even if it finds one, the model won’t be so accurate. So it’s worthy of time to clean the training data set. Actually data scientists spend a lot of their time doing the cleaning job. They will either abandon the apparently abnormal samples or try to mend fix the errors manually. Both are useful. For samples where certain characteristics are missing (ages of 5% customers are absent, for instance), they will make a decision – to ignore the characteristic wholly or to ignore the samples with this characteristics missing, or to supply the values, for instance, by filling in the median, or to train another model without this characteristic.
It’s time- and effort-consuming. Yet an automatic modeling tool encapsulates the rich experience of a statistician to do the jobs as well. It makes the modeling process faster and simpler, for both data scientists and novice data miners.
2. Lack of skilled data miners
Though it’s often the case that a data mining project is led by the IT team, professional statistical skills are needed. The job is hard for ordinary IT people, so the implementation of the project could be not so smooth.
The choice of algorithm is at the core of a data mining project. Statistics is the theoretical base and databases provide computational power. It’s the joining forces of mathematics, statistics and computational science that are needed to build a successful model. Knowledge of these subjects and related experience are thus the essential abilities of a qualified data miner.
SAS, R and Python are the most favorite modeling tools/languages are. As powerful as SAS, it still requires a certain amount of manual work. Besides, the tool has a high threshold. Only data scientists who have a solid statistical background can handle it well. But they are rare and expensive. It’s hard to use for most of the ordinary data miners. R and Python are the preferences of programmers who are accustomed to do the mining analytics through programming. But even the most excellent programmers will have to make the shot in the dark only to build an ineffective model if they don’t know the statistical knowledge and without the data preprocessing experience.
The cost of employing data mining engineers is also expensive. Only the headquarters of big companies can afford a small data mining team. The quality of manual modeling, which is the mainstream way of model building, is, to most of the degrees, determined by the skills of the modelers. Based on same data, modelers of different levels of skills build completely different models. This leads to unstable modeling quality. On the other hand, the flow of modelers has a negative impact on the data mining project. Even an update of an existing model by a newly employed modeler needs a do-over of the whole modeling process.
Automatic modeling techniques have taken a big leap forward these years, which provides solutions to all the problems. The techniques require a much lower threshold of being a good data miner. After getting simple training, an average technician or employee can master the data mining skills. It’s cheaper, easier and faster for companies to train a lot of qualified modelers. The auto-modeling techniques support creating a model factory, which can automatically build stable and quality models and protect the data mining project from the flow of human resources.
The following picture lists the required mining skills and the model features for the manual modeling and the automatic modeling. Apparently, an automatic modeling tool has a very low threshold but generates more effective and stable models.
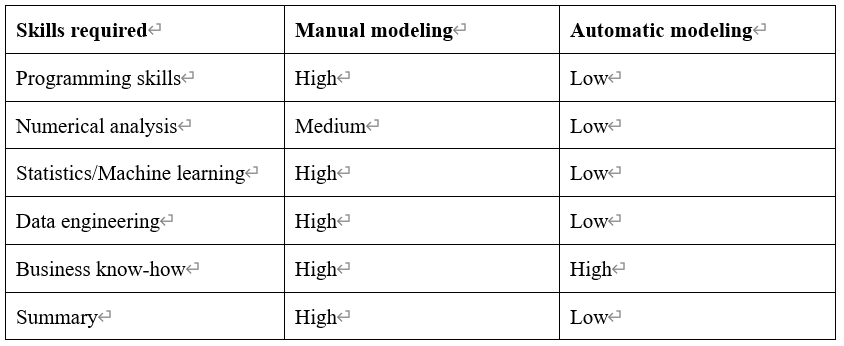

- Low modelling efficiency
The mainstream modeling tools are Python and SAS. They only support manually exploring data, preprocessing data, adjusting model parameters and evaluating model performance. It takes even data scientists or skilled modelers several weeks to several months to complete a modeling project. Such low efficiency limits the application of data mining technologies.
Yet the needs of building models for various business scenarios are still there. Even one scenario requires more than one model to get business done. Models can help to efficiently identify potential target customers and increase business success rate in a precision marketing project. But as manual modeling is only able to build a universal model simply on all customers nationwide due to its extremely slow process, it cannot adapt to the marketing policies and consumer characteristics in different regions, the various interests of customer groups in even the same region, and the reality that customers may buy several kinds of products at a time or during a period.
Automatic modeling is a way out of the dilemma. It can build a model in as fast as several hours, compared with the weeks of time spent by manual modeling. Since we are able to build a series of models in a very short time, we’ll make a better prediction about our targets.
Efficiency is particularly important for certain businesses because market fluctuates rapidly and thus models need to be constantly updated. A manual update is nearly a rebuilding of the model. It involves another round of data preprocessing, parameter adjustment and other things. It will take longer and more effort to do the update if there happens to be some changes of the modelers. Such efficiency cannot meet the business development requirements. Automatic modeling, however, is convenient and fast. You just need to define a condition for triggering the update (a specific time point or a certain value) and update will be automatically performed.
The inefficiency of manual modeling, from an economic point of view, results in expensive models. The cost is at least 50,000 dollars per model. Automatic modeling is several times more efficient and much cheaper, and thus can be widely applied.
5. What are the differences between veterans and novices?
The modeling phase is the core of the whole data mining workflow. All the other phases exist to serve it. The implementation of that phase is the touchstone of the modeling skills.
Machine learning experts have contributed various ready-to-use algorithm packages. scikit-learn, for example, provides an algorithm library of regression, dimensionality reduction, classification, clustering, etc. Users can effortlessly build a model by calling a package. But to build a high-quality model, that’s far from enough. Different from the database sorting and grouping algorithms that will have same outputs for same inputs and that only need to configure a few parameters at most, data mining algorithms, whose implementations involve a lot of experiential factors, will probably have different, even disparate, outputs for same inputs with different parameters. The GBDT algorithm, for example, requires a dozen of parameters (as shown in the picture below). Modelers need to have a deep understanding about the algorithm principle and application scenarios to get their meanings correctly, configure them properly, find optimal values quickly and adjust them correspondingly if the model performances are not satisfactory. But first, the modelers need to choose the most suitable algorithm or the best combination of algorithms.

Yet the data preparation before model building is more complicated. That often involves the handling of non-normally distributed variables, noisy data reduction and high-cardinality variables. A veteran modeler has a solid base of statistical theory, the rich experience of parameter adjustment and a firm grasp of the principle of data distribution, data preprocessing and algorithm implementation. While a novice, with shallow theoretical base and poor data exploration and analytic skills, isn’t good at processing data according to the modeling target and is only able to do the package invocation. They simulate but don’t know the reasons behind. They are like the people who know nothing about architecture but possess raw materials building a house. It’s lucky that the house is habitable and durable.
Fortunately the burgeoning automatic modeling technologies enable novices to handle the data mining work like veterans. An automatic modeling tool encapsulates the mathematical and statistical theories and rich data mining experience to be able to automatically perform data preprocessing, build models, configure parameters and evaluate model performance. Users just need to input data into the tool and configure their target to get a quality model. Any programmers, or even beginners without any statistical background and unfamiliar with data mining algorithms, can deal with a data mining project using such a tool.
6. Why can’t I build the same effective model with open-source tools?
There are varieties of open-source tools for data mining. scikit-learn, one of the most popular ones, offers a lot of algorithms, including Regression, Dimensionality reduction, Classification and Clustering, to enable users to build models in a flexible way. But performances of models built by different users using the same open-source tool can be quite different. Models built by data mining experts are always more effective than those built by ordinary modelers. There are three reasons for this.
First, the quality of raw data is poor. As I said before, data mining is like mining gold. High-quality data is easy to mine and yields excellent results; while poor-quality data is difficult to mine and yields poor results. There are two aspects to consider. There should be enough data to be mined. Most of the machine learning algorithms requires a certain amount of data, particularly enough positives, to work. Too few data leads to failure or ineffective models. Data samples and characteristics need to be sufficiently typical and relevant for building an excellent model. To predict the presidential election results as accurate as possible, for example, the polling samples should be comprehensively represented, rather than partial to certain groups or regions.
Yet even based on the same data, different modelers generate models of disparate quality.
Second, data is not properly preprocessed. The raw data should first be prepared before being used for model building. The way it is prepared has a big influence on the model building results. But data preprocessing is not simple because there isn’t a definite method for doing that. You try and choose a method according to data characteristics and distribution. That’s why a copy of data mining workflow using an open-source tool can’t ensure the same result. Take the handling of missing values as an example. If 5% customers in the raw data haven’t age values, you need to make a decision of how to handle them. To ignore the age variable or the samples that containing the missing values, or to fill the empty fields with mean or median of the column or using a more complicated method, or to train two models where one contains this characteristic and the other doesn’t contain the characteristic. And when the missing rate reaches 90%, you should consider if the algorithm you choose is still suitable. Sometimes the raw data may contain errors, abnormal values and noisy data. In such cases an algorithm is hard to discover a pattern if the data isn’t properly prepared in advance. Other times you need to take good care of the high cardinality categorical variables, non-normal distribution and time series data.
Data preparation is the key phase of a data mining project. So data scientists and veteran modelers will spend time preprocessing data. The point is that you need solid statistical theory and a rich experience of data analytics and a lot of tries to be able to do that. Copying an existing data preprocessing workflow, or skipping the preprocessing phase, for model building will depend on luck to have an effective model.
Third, parameters are not appropriately configured. Different from the database sorting and grouping algorithms that will have same outputs for same inputs and that only need to configure a few parameters at most, data mining algorithms, whose implementations involve a lot of experiential factors, will probably have different, even disparate, outputs for same inputs with different parameters. The GBDT algorithm, for example, requires a dozen of parameters (as shown in the picture below). Modelers need to have a deep understanding about the algorithm principle and application scenarios to get their meanings correctly, configure them properly, find optimal values quickly and adjust them correspondingly if the model performances are not satisfactory. But first, the modelers need to choose the most suitable algorithm or the best combination of algorithms.
The biggest advantage of open-source tools is that they are flexible and so they almost can manage any requirements. The disadvantage is that the quality of result completely relies on the skills of modelers. One is hard to build a great model if they haven’t relevant statistical and mathematical knowledge, and are not good at preparing data, selecting the best model, configuring parameters and evaluating models. The algorithms and functions provided by an open-source tool are like semi-manufactured building materials. You also need to be familiar with a lot of other things, including the architectural structure, materials science, mechanics, fluid mechanics and HVAC engineering, etc., to build a safe and suitable residence. Without these knowledges, you are just assembling parts rather than build.
Automatic modeling provides a great alternative for novice modelers and ordinary programmers to engage in data mining projects. Such a tool is packaged with statistical and mathematical theories and excellent data processing experience to be able to preprocess data, build models, configure parameters and evaluate model performances automatically. It’s easy to use. Users just need to input data into the tool and configure the targets to get an effective model.
7. Why is Python the most popular language for data mining?
Python is the most popular choice for data science and AI. The programming language has become the focus of many AI crash courses. Even a lot of people outside of the machine learning field have taken an interest in the language. Maybe that’s why some machine learning beginners believe that AI is about Python programming. But my concern is the reasons behind the Python phenomenon.
(1)Rich class libraries
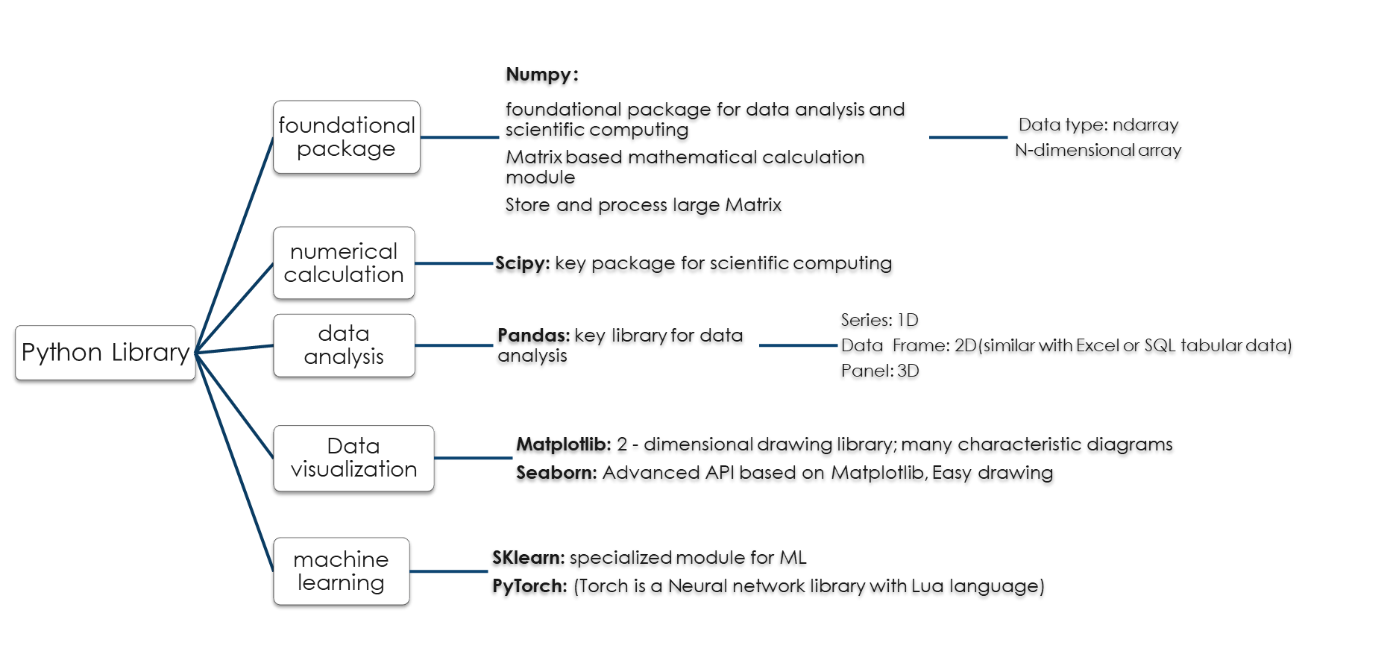
By establishing and nourishing a large, active scientific computing and data analytics community across the world, Python has grown into one of the most important languages for data science, machine learning, and academic and industrial software development. Its popularity for data analytics depends heavily on its support of a variety of class libraries. It depends on Numpy (Numerical Python) as the cornerstone to offer basic data structures, algorithms and most of the interfaces for numerical computations. Python pandas provides advanced data structures and, by combining the flexible data manipulation abilities of the spreadsheets and relational databases (such as SQL) with Numpy’s array computation feature, a rich library of basic functions to effectively simplifying the data cleansing and preprocessing workflow. Matplotlib is the most popular comprehensive library for creating static, animated and interactive visualization in Python to help analysts observe data in an intuitive way. scikit-learn is a Python module for machine learning born in 2010 and has become the preferred choice among programming. The free software machine learning library, composed of a lot of submodules including classification, regression, clustering, dimensionality reduction and module selection, is maintained by 1500 coders from all over the world. It is these class libraries that make Python the most effective scientific programming language. With Python, a veteran data professional manipulates data as flexible as they can to build the desirable models.
(2)Easy to learn & use
Python programming features simplicity. Reading a well-arranged Python code snippet is like reading an English paragraph. The code is very similar to our human way of thinking. It’s simple and pure and focuses on the solution to the problem rather than the syntax design. We can say that Python is the only language that doesn’t need comments.
The free of charge and open-sourceness are part of the reason for its popularity. Users are free to use Python for software development or to publish applications without any payment and copyright issues. It’s also free for commercial use.
With the two features, Python’s leadership position is thus established.
But, Python and AI are different things. Mastering Python programming won’t ensure you an AI expert. Though powerful, Python is just a programming language. Yet the core of AI is algorithms. Behind these algorithms are theories of statistics, calculus and probability. There is no AI without algorithms.
Implementations of AI algorithms are complicated. It’s not practical to write programs from scratch. But Python provides ready-to-use algorithms. So people turn to Python. Actually if a language or a tool supports similar class libraries, they can also enable convenient model building. But a programmer knowing Python cannot necessarily build effective models if they don’t understand relative mathematical theories and don’t know how to properly process data, select models, configure parameters and evaluate models.
So it’s not enough to build great models with modularized Python functions only. Modelers need to be familiar with relevant mathematical theories. Otherwise they will depend on luck to get excellent model building results. The core AI is mathematics and Python is a wonderful tool to get to the point.
Automatic modelling technologies offer a way out for ordinary IT workers without statistical and algorithmic knowledges. An automatic modeling tool is intrinsically equipped with the data processing theories and experience and thus can “intelligently” perform all data mining phases including data preprocessing, model building, parameter configuration and model evaluation only if you input data into them and define your target. With such a tool, you can save the time and money for learning Python.
8. Is an AI crash course necessary?
The “Python phenomenon” brings in business opportunities. You have a great chance to discover that, after reading through a new push about Python and AI in your regularly browsed app, it is an AI program advertorial. So do we really need to enroll in an AI course? Or how much does such a course help you?
Generally there are three types of AI programs.
One is the Python course under the banner of AI program. Some training sessions even claim that knowing Python is grasping AI concepts and techniques. They teach you how to build models but not how to build performant models. To build a data mining model, for example, you need to have solid statistical theoretical foundation, extensive experience of model building and parameter configurations, and a deep understanding about the principles of data distribution, data preprocessing and algorithm implementation. One who knows only Python for model building scratches only the surface of AI. The core of AI is algorithms driven by mathematical theories of statistics, calculus and probability. You’ll never grasp AI without getting a grip on algorithms. Python is the popular tool for implementing the AI algorithms because it’s powerful, simple and easy to use and because it supports a wealth of ready-to-use class libraries. It’s not irreplaceable since other languages or platforms, like R and SAS, can be used to build modes as conveniently if they support similar class libraries.
The second type of training program inculcates AI concepts but doesn’t teach implementation. It is like castles in the air, impractical, I mean. They implant a bunch of ideas in you but in the end you don’t know how to apply them in real-world model building tasks. This type of course is seldom seen now.
The last type focuses on teaching algorithms. This is the truly useful AI course. And it is difficult. Machine learning is an interdisciplinary field. Besides programming, it also requires knowledges of probability, statistics and calculus. Deep learning is a subset of machine learning and an independent research area. One or two months are too short for grasping any of these subjects. Taking an algorithm course doesn’t mean you can grasp it. In fact most learners cannot. It takes a certain amount of mathematical knowledges, time and effort to understand and master algorithms. For example, you need to watch the video of regression algorithm four to five times to basically understand it. More time and effort are required to be able to use it flexibly. It’s not easy to become an algorithm engineer since the AI field has a relatively high threshold.
Since AI courses are difficult and useless, is there any way for data mining beginners to better continue with their careers?
Of course there is. The automatic modeling tools are designed for novices and beginners. They have technologies that encompass the past excellent data processing experience and concepts to enable automatic workflow of data preprocessing, model building, parameter configuration and model performance evaluation. Data and target in, models of high quality out. The tools require little of mathematical theories and knowledges. Modelers only need to be familiar with the basic concepts, particularly the model evaluation methods, and leave the complicated preprocessing, algorithmic principles and parameter configuration to the professional tools to handle. The automatic modeling tools are suitable for everyone who wants to do data mining.
9. What is deep learning? What can it do?
Deep learning is hot as machine learning flourishes. It is part of the broader family of machine learning algorithms. The following picture shows the relationship between AI, machine learning and deep learning. Machine learning is a subset of AI and deep learning is a subset of machine learning.
Not a new concept any more, deep learning is based on artificial neural networks that were introduced as early as in 1940s. At that time, computers were in its infancy and crawled for days to train the simplest networks. In a dozen of years, the application of artificial neural networks came to a standstill due to the computers’ inefficiency. In recent years, there have been significant advances in neural networks research thanks to the increase of computers’ speed and the prevalence of GPU and TPU. And the success of AlphaGo has made quite a name for deep learning.
There are supervised and unsupervised deep learning algorithms. Convolutional Neural Networks (CNN) is a class of supervised deep neural network and Deep Belief Nets (DBN) is an unsupervised deep neural network. The depth of deep neural networks (DNN) is the number of hidden layers between the input and output layers. The more the hidden layers, the deeper the networks become.
And the more complicated the task, the more the layers and neurons in each hidden layer are needed. The AlphaGo networks have 13 layers for learning strategies and each layer has 192 neurons. Deep learning methods aim at learning feature hierarchies by constructing a lot of machine learning models to train massive amounts of data in order to increase the accuracy of classification and prediction.

Deep learning methods train computers to automatically find patterns and features from data. It combines the feature learning into the model building process so as to reduce the manual errors as many as possible. But with limited amount of data, deep learning algorithms cannot perform an accurate prediction about data patterns. They need massive amounts of data to increase accuracy. The complexity of graphical models entails a surge of time complexity in deep learning algorithms. Higher parallel programming skills and more and better hardware are needed to ensure that the algorithms are implemented in real time.
Deep learning has its limits. Currently it is mainly used for image recognition and speech recognition. Other commercial scenarios, however, have not seen a satisfactory application. Overfitting is common. A model that performs well over training data but has poor generalization ability cannot find pattern as expected from new data. That has proved fatal in machine learning strategies. Machine learning models are easy to be affected by tiny changes of the target data and prone to be deceived into wrong prediction or classification. But noises exist widely in real-world scenarios. The nontransparency of deep learning process for decision gives us no opportunity to see through its mechanism. So in some cases it’s difficult to use. A deep learning model for approving bank loans, for example, refuses a client’s application but cannot provide an explanation and the user is understandably reluctant to accept the result. Natures of deep learning technique restrict its applications. They include massive and extensive training data, complicated algorithms, slow model training that usually persists for days or weeks, and heavy resource consumption.
Deep learning, as other machine learning algorithms, has its merits and demerits. Suitable algorithms are the best algorithms for solving problems in real-world business scenarios. Some automatic modeling tools encapsulate deep learning algorithms to be able to automatically preprocessing data and choosing the optimal algorithm to build performant models. Users just need to input data and wait for the result.
10. Why business knowledge is crucial for building effective models?
To perfectly handle a data mining project, a modeler should both have great technical competency and fully understand the business. The technical abilities cover statistical analysis, algorithm implementation and computer literacy. Business knowledge refers to the capability of understanding the current model building project or task. Both are indispensable through the whole model building workflow and have an impact on the final result. But the latter’s importance is often ignored.
The first and foremost thing to set about building models is to understand the project and the target data. This includes understanding on project background, mining object, and modeling data. The goal of model building is to solve business problems. Business targets are the direction of all data solutions and determine the nature of data mining project, and where and what you should mine. To find the potential high-risk clients in a loan risk prediction project, for instance, it’s important that how you define a high-risk client. Clients who have had payment defaults belong does not necessarily belong to the high-risk group because a further analysis plus business common sense can decide that the occasional defaults are merely several days overdue due to neglect. Another instance is the precision marketing. Is it necessary to build models over different client groups or on different regions? That’s the first thing you should consider. You cannot make the right decision if you don’t understand the business needs well. To define a range for modeling data also needs sufficient business understanding. Otherwise you make the effort only to get little. In the first data mining phase, business understanding is the dominant skill and technical ability helps. In the model building phase, business process optimization goes before modeling approach optimization which is more important than modeling technique optimization.
After defining the modeling target and data, you move into the data understanding phase. The object of the second phase is to create a data mart or a wide table by selecting, cleansing, constructing, combining and formatting data. Business knowledge is also important here. The data for model building may come from multiple tables or data sources and you need to know the logical relationship between them to combine them (For example, table A contains orders data, table B contains product attributes data, and table C is client information). You cannot get their relationship correct if you know nothing about businesses. You may also need to do a lot of data merges and characteristic extraction. In the raw orders data, one user may have multiple IDs, one ID could correspond to multiple orders, and one order may contain multiple products. You need to be very familiar with the businesses to know their correspondences clearly. It would be best if you have some ETL skills. But most of the time the IT team has already built a data warehouse, so there is no need to worry if you don’t know how to perform the ETL process.
The data preparation and modeling phases require higher technical skills, including statistical analysis, algorithm implementation and parameter configuration. This is the hardest part of the data mining project which is difficult to handle and where experts are rare. This gives a false impression that data mining is all about technical ability and business knowledges are not that important. Now part of the technical work can be achieved by AI. The emerging automatic modeling tools can deal with the data preparation and modeling jobs autonomously. Their power comes from the encapsulated data processing ideas and experience many statisticians and mathematicians. They can do a series of data mining jobs, data preprocessing, modeling, parameter configuration and model performance evaluation, autonomously. All users need to do is to input data and configure the target. Then they can sit down waiting for outstanding models generated automatically. Even the novices without statistical background and algorithmic knowledges and ordinary programmers can use such a tool to build high-quality models.
Being able to identify the best model is also important. You should know about a list of matrices for evaluating models, including AUC, ROC, Gini,Lift,MSE, etc. About business understanding, you should learn to select the right matrices for model evaluation according to the business target. The following are confusion matrices of two models for choosing the potential target customers in order to sell 50 pieces of a product. Which one do you think is the better?
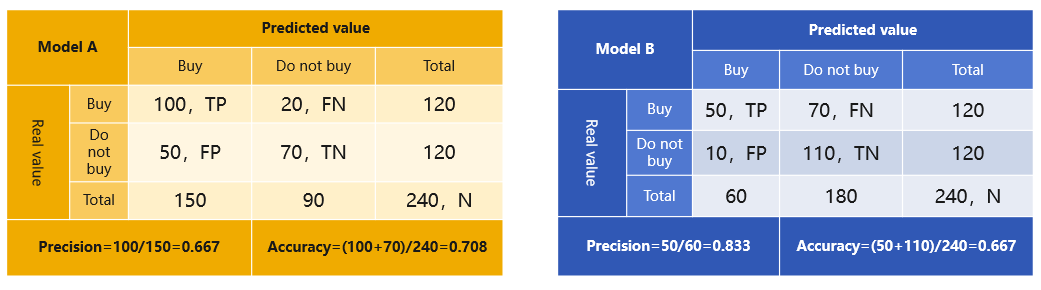
Model A is the right one according to accuracy rate only. In this case we have 75 people (=50/0.667. The 0.667 is the accuracy rate, which means 66.7% of the predicted number of people will be the actual purchasers) to persuade in order to sell 50 pieces. We only have 60 (=50/0.833) people to persuade in order to get the target done if we choose model B, which has a lower marketing cost. So we need to be target-oriented when choosing matrices for model evaluation.
So both technical skills and business knowledge are essential for building effective, high-quality models. You can use an automatic modeling tool to handle the hardest technical part of data preprocessing and modeling, but can only learn business knowledge by yourself.
11. What are the benefits of batch modeling?
Since data mining techniques are difficult to learn and the algorithms are hard to implement, one data mining project is able to build one model only. The model is thus intended to be as widely-applied as possible but, as a result, becomes less scalable. To achieve higher scalability, we need multiple models.
There are various business scenarios, so different and many modes are needed on the demand side. Usually a series of models instead of one is required to achieve a single business target. Using models in precision marketing helps to find potential target customers more efficiently and to increase marketing success. Generally only one model is built for customers in the whole country. Yet the reality is that marketing policies and customer habits vary according to areas and that, even in the same area, different customer groups have their own interests. Apparently the one model is not scalable at all. Building models on different areas and customer groups can increase model scalability. Besides, there could be dozens of or more products are being marketed and a great number of models are needed. Cash flow management is critical in providing financial services and bank loans. Models can be built respectively for incomes and expenses to predict cash flow status accurately. Then more models can be built on different classifications in both sides, by product, for instance. A total of a dozen of or dozens of models are needed to get an accurate prediction about cash flow. Batch modeling is thus what the business predictions really need.
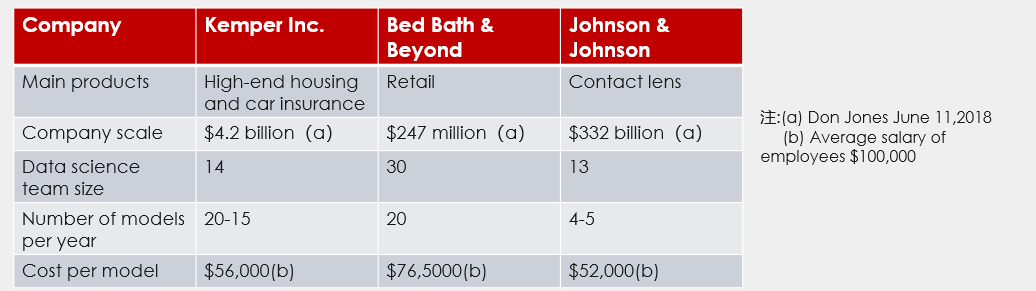
On the supply-side, however, manual modeling using tools like SAS or Python open-source packages is common. Each model is built through manual data exploration, data preprocessing, and parameter configuration. It takes at least several weeks or months to build one model. That’s extremely time and effort consuming. Modelers are expensive too, which results in an average high cost per model. The following picture lists the cost of model building in three American companies. They pay each employee in the data analytic team an annual salary of 10,000 dollars at least (the actual payment is much higher, though), and the cost for each model is evaluated as over 50,000 dollars. In view of the time and economic cost, it’s impossible to achieve batch modeling manually. In a word, manual data mining projects are both inefficient and ineffective.
Data mining projects using the automatic modeling technique will be fast and resource-saving. The automatic modeling tool can handle data exploration, preprocessing, model selection, parameter configuration and model evaluation autonomously, and reduces the whole workflow to several hours or even several minutes. Modelers just need to deal with the business understanding and data preparation phases and leave the rest of the iterative model building work to the machine. Once the data mining process becomes simple and fast, batch modeling is feasible. We can build a number of models in one day and each model focuses on a part of the target or a smaller target. A group of models is more scalable. Automatic modeling tools have a much lower threshold. They enable data mining novices and ordinary programmers to have a more capable access to the data mining work. One person can handle the concurrent batch modeling job, for example. The batch modeling will in turn reduce the cost and make the modeling technique more applicable.
12. What is the attenuation of models?
Generally we are more concerned with a model’s precision and recall and ignore another important matrix, the attenuation of models. Attenuation is the variation, usually decline, of a model’s performance during its actual uses.
Data mining is essentially the action of discovering pattern in the things happened in the past (historical data) and predicting future according to the pattern. So the to-be-predicted future must be the continuation of the familiar past. The reality, however, is constantly changing and so does the historical data. That means the pattern is ever-changing. From this perspective, the data set used for training a model represents the pattern in a certain period and is static. When reality is changed, the pattern becomes inaccurate. Using models of outdated pattern to predict future will get inaccurate result. That means the model performance declines. A house price model built on data from 2010 to 2020 is able to accurately predict the house prices in 2021 but it will be rather inaccurate when used to predict house prices in 2050. That’s because the real estate market will be seeing a constant change in the following decades.
But how can we judge the attenuation level of a model? To put it simply, we compare the matrices of models on training data and test data. The differences reflect their levels of reduction on the to-be-predicted data (the future data). The picture below shows model A and model B that are built on the same data set, and their AUC values on training set and test set respectively (AUC is a common matrix for evaluating models and its value range is 0-1; the higher the value the better the model). Model A is better if we consider only the AUC values. But when we look at the matrix’s change in training data and test data, we find that model A has a higher attenuation level and is overfitting at some degree. Model B, though its AUC is smaller, has lower attenuation level and better generalization ability, and it is more stable. It is more accurate than model A in predicting future in practical uses.
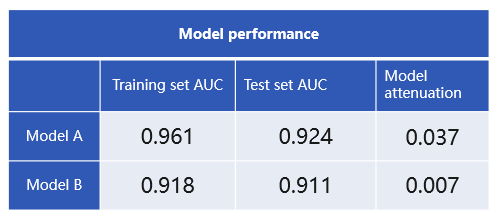
As a model has its life cycle, we should not expect it to remain effective forever and in all scenarios. Its precision begins to decrease after being deployed and doing the job in a business scenario for a certain period. When it lowers to a certain threshold value, we should consider giving it up and building a new one. Rebuilding a model involves a new round of data distribution analysis, data preprocessing, algorithm selection and parameter configuration. You go through the same workflow and spend nearly the same effort. It’s even more complicated if the modeler doing the update isn’t the one who initially builds the model. The model update will be convenient if there is an automatic modeling tool. Users only need to define a trigger condition (such as per month or a certain AUC value) and the tool will update the model autonomously.
Equipped with data processing experience and ideas of numerous statisticians and mathematicians, an automatic modeling tool is able to handle data preprocessing, model building, parameter configuration and model evaluation on their own. You input data in and configure the target, and the tool generates a high-quality model. Everyone, including ordinary employees and programmers, can manage a data mining job using the automatic tool.
13. Is the higher the model precision the better?
There are many model building approaches for choice in a data mining project. They include linear regression, logistic regression, decision tree, and ensemble algorithm. After a model is built, we have matrices and graphs to evaluate its performance. We can’t say that the goal of data mining is achieved by finishing constructing a predictive model because we need to make the model as applicable on other data as on the training set and to be as highest precise as possible. So it’s important to evaluate the model precision before we set to score the data and get a result.
There are a lot of matrices for evaluating models. To evaluate classification models, we have accuracy, recall, lift, etc. Why do we need so many matrices to measure the quality of a targeting model?
I’ll explain this using an example. We build a model to identify terrorists in an airport where we assume 5 can be found per one million people. That’s a rather low probability. If we only use accuracy to measure the model’s performance, the model can be 99.9995% accuracy if it can identify all people within the defined area as normal. Apparently such a model is useless. So we need to build one with high recall. Below are the confusion matrices of two models:
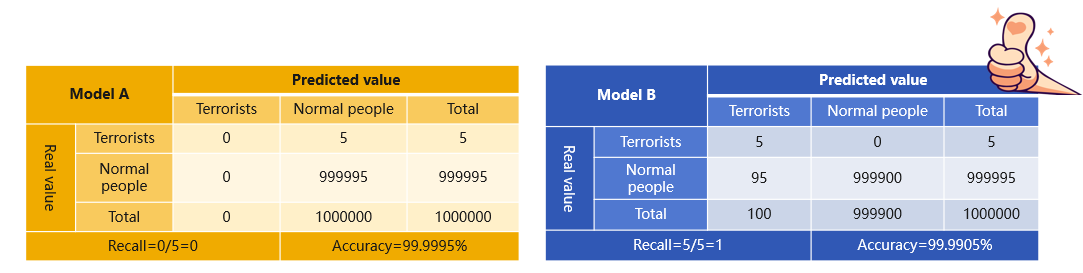 Model A has high accuracy but it cannot identify any target. Model B is lower in accuracy but it can recognize all targets though probably a number of non-targets are included at the same time. It’s better than nothing. In such scenarios where positive samples and negative samples are extremely imbalanced in number, we are usually concerned with the minority samples only. So it makes no sense to focus merely on accuracy. Another similar scenario is to predict the default rate, where we are more concerned with the high-risk clients rather than the high-quality ones. It’s more probably that the high-risk clients can be found with a higher recall. Other scenarios include the diagnosis of cancer, settlement risk prediction and the defective products identification.
Model A has high accuracy but it cannot identify any target. Model B is lower in accuracy but it can recognize all targets though probably a number of non-targets are included at the same time. It’s better than nothing. In such scenarios where positive samples and negative samples are extremely imbalanced in number, we are usually concerned with the minority samples only. So it makes no sense to focus merely on accuracy. Another similar scenario is to predict the default rate, where we are more concerned with the high-risk clients rather than the high-quality ones. It’s more probably that the high-risk clients can be found with a higher recall. Other scenarios include the diagnosis of cancer, settlement risk prediction and the defective products identification.
Here’s an example about accuracy judgement. To sell 50 pieces of a certain product, a company has built two models to find the potential customers. Below are the confusion matrices of the models. Which is do you think the right one?
Model A is the right one when we focus on accuracy. In this case we have 75 people (=50/0.667. The 0.667 is the accuracy rate, which means 66.7% of the predicted number of people will be the actual purchasers) to persuade in order to sell 50 pieces. We only have 60 (=50/0.833) people to persuade in order to get the target done when we choose model B, which has a lower marketing cost. Since the potential customers to buy the product are what we need in this case, the accurate prediction of non-target customers makes no practical sense. Precision is thus the right matrix to evaluate the models.
So sometimes it’s not that we cannot build great models, it’s the wrong matrices we use to measure the model that lead to unsatisfactory result. Matrices have their own scenarios to play a role. Accuracy is one aspect, but you need to take the whole business picture into account to choose the right matrices. We can also use graphs to evaluate the performance of models. There are the ROC curve, lift curve, precision-recall curve, and the residual plot used for assessing a regression model. It’s tedious to calculate the matrices and plot the graphs manually. Now it’s convenient to do the work thanks to automatic modeling tools. An automatic tool can calculate all matrices. Users just need to know how to use them properly.
SPL Official Website 👉 http://www.scudata.com
SPL Feedback and Help 👉 https://www.reddit.com/r/esProc
SPL Learning Material 👉 http://c.scudata.com
SPL Source Code and Package 👉 https://github.com/SPLWare/esProc
Discord 👉 https://discord.gg/ydhVnFH9
Youtube 👉 https://www.youtube.com/@esProc_SPL

